AI Weekly #004
🆕 What's New?
Product Updates:
- Support for exporting workflows.
- The application supports automatic updates.
- Fixed various installation error issues.
- Fixed some UI display misalignment issues.
- Fixed the issue of exporting images without workflow parameters.
New tutorials added last week:
- How can ComfyUI be applied interior design? (opens in a new tab):We explored how ComfyUI can perform exceptionally in interior design. Additionally, we recommended some models and plugins to help those interested in interior design make better use of them.
- Model Recommendations (opens in a new tab):Considering many new students often ask for model recommendations, the tutorial website has added a model recommendation page, and will continue to recommend more models suitable for everyone.
🤩 Weekly‘s AI highlights
📄 Noteworthy papers and technic
It is a framework that utilizes LLM (Large Language Model) to optimize the SD (Text-to-Image) text-to-image conversion process. This framework is capable of better understanding and deconstructing the textual prompts for image generation, enabling the division of an image into different parts or regions. Based on the understood corresponding textual prompts, it generates images for each section, and then synthesizes them into a final image that meets the expected requirements. The main functions of the RPG framework include multimodal re-tagging, thought-chain planning, supplemental regional diffusion, high-resolution image generation, diverse applications, and compatibility with different types of large language models. Because it uses advanced large language models, this framework can be directly applied to text-to-image conversion tasks without the need for additional model training.

It only requires a single facial photo and can generate different styles of portraits in a matter of seconds. Unlike traditional methods that need multiple reference images and a complex fine-tuning process, InstantID requires just one image and eliminates the need for intricate training or fine-tuning. It achieves high-fidelity personalized image generation without complicated training or adjustment processes. This tool boasts strong compatibility, high facial fidelity, and text editability. Its applications are diverse and practical with high efficiency. It supports multiple references to obtain more information and inspiration, enhancing the richness and diversity of the generated images.

Utilizing multiple photographs as identity IDs, this technology captures individual features to create a new, personalized character image. It can generate character photos that match descriptions, as well as blend features from several different individuals to create an entirely new character. Additionally, it can alter the gender, age, and produce various other styles of photographs for the character in the picture. The process is quick, realistic, and the results are natural-looking.

Driven by LLM (Large Language Model), the text-to-image generation system developed by ByteDance, DiffusionGPT, stands out for its integration of expert image generation models from multiple domains. It utilizes the LLM to interface with these image generation models, allowing the LLM to process and understand various text prompts (including specific instructions, abstract inspirations, complex hypotheses, etc.). Based on the information comprehended, it then selects the most suitable image model to generate the image. This approach enhances the ability of the system to produce images that are closely aligned with the textual input, showcasing the power of combining advanced language understanding with specialized image generation technologies.

🛠️ Products you should try
Three new features have been introduced: Text-to-Image, Background Removal, and Eraser. With these tools, you can easily edit any image and freely combine various images. When you use tools on the left side, the AI on the right side automatically generates images in real-time, greatly enhancing the convenience and freedom of creation, allowing for truly boundless imagination...
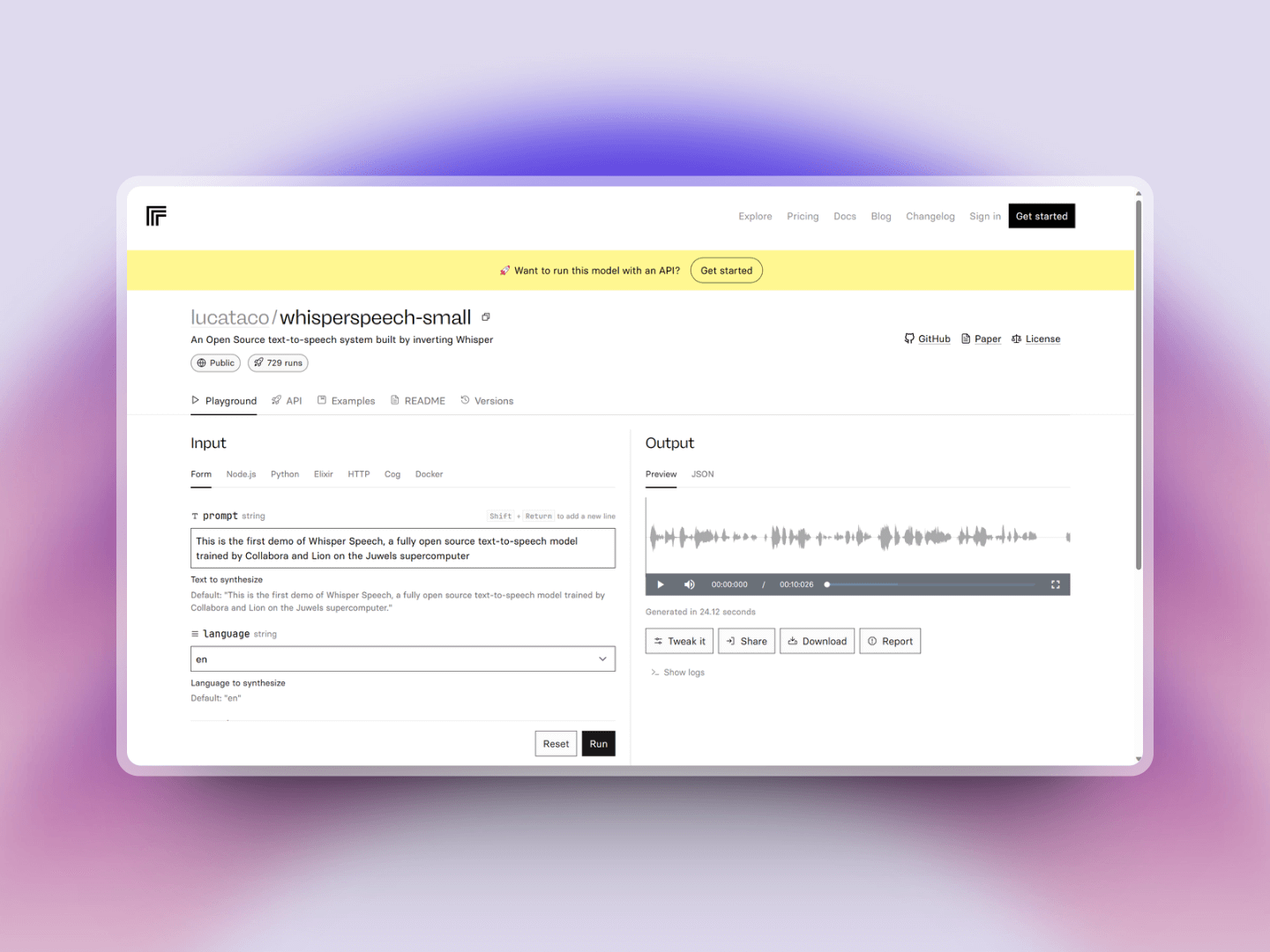
WhisperSpeech is an open-source text-to-speech system, achieved through reverse-engineering OpenAI's Whisper speech recognition model. Through this inversion process, WhisperSpeech can receive text input and use the modified Whisper model to generate naturally sounding speech output. The output speech is exceptionally good in terms of pronunciation accuracy and naturalness.
Multi Motion Brush is a tool designed for precise motion control. It allows you to use different brushes on an image to control the motion state of various parts of the image. You can select different brushes to add or change actions within the image, with each brush having its own unique effect.
HeyGen is an online digital human video production platform that harnesses the power of generative AI to simplify the video creation process, enabling quick and easy creation of professional-level videos. They also offer a "video translation" feature, which seamlessly integrates "language translation + voice synthesis + lip-syncing to beats," allowing celebrities like Taylor Swift to speak authentic Chinese in videos. The latest feature demonstration of HeyGen reveals that it is now possible to have video chats with AI, meaning you can converse with a robot using text. The robot has a tangible image and can chat with you through video. The characters, voices, and responses in the video are all AI-generated.
