AI Weekly #008
🆕 What's New?
Product Updates:
- Released ComflowySpace v0.0.8-alpha, the Load image node supports the Mask editor function, and the dropdown menu has added an image preview feature, making it easier to select images.
- The Model Tab has added a model recommendation feature. You can see the models we think are worth downloading from here.
- Download link:Comflowyspace (opens in a new tab)
New tutorials added last week:
🤩 Weekly‘s AI highlights
📄 Noteworthy papers and technic
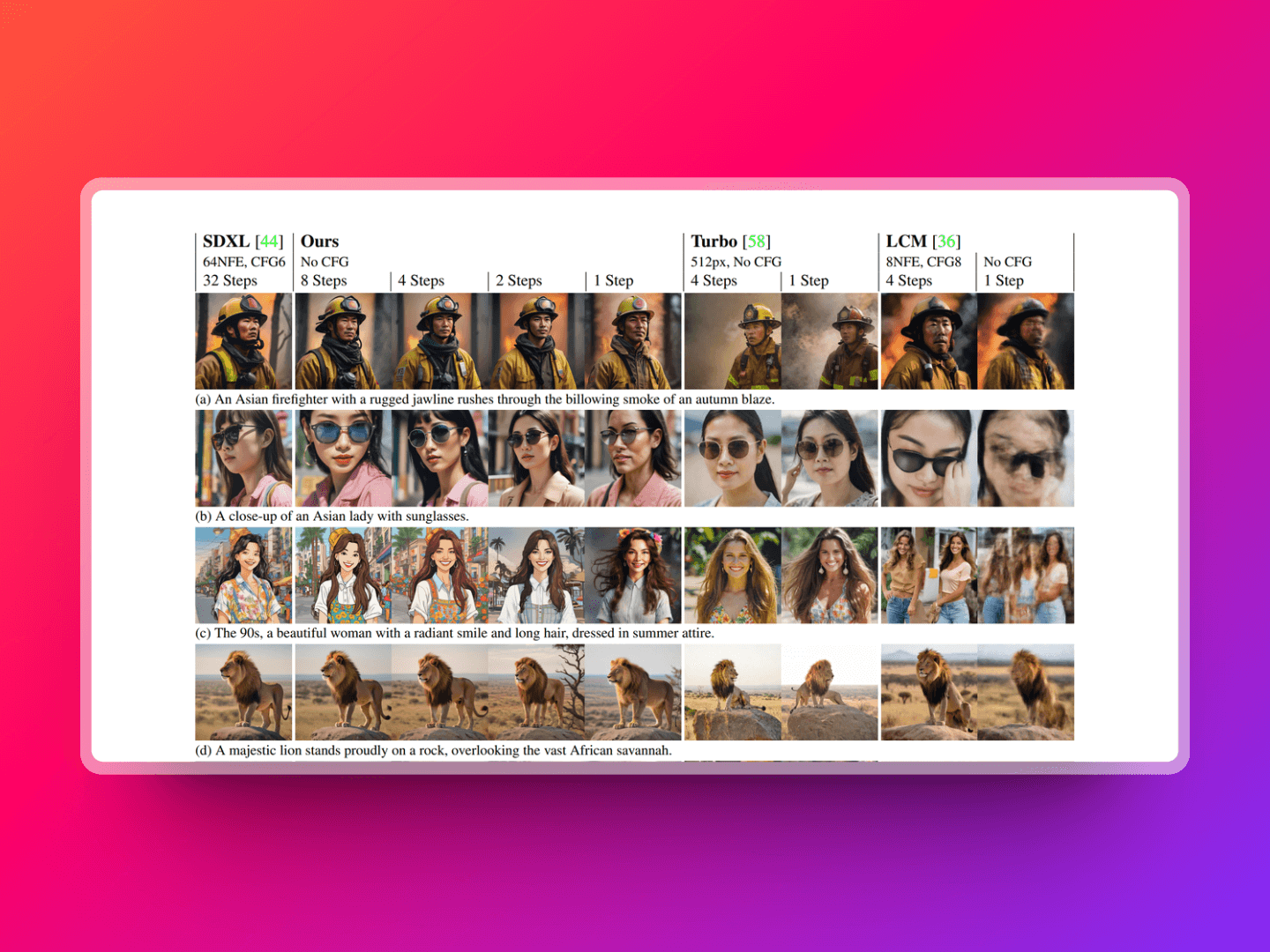
ByteDance has released SDXL-Lightning, a model that improves distillation effects through Progressive Distillation and Adversarial Distillation, allowing for the generation of high-quality 1024px images in just a few steps. In both quantitative and qualitative comparisons, its performance surpasses that of Turbo and LCM. Similar to LCM-LoRA, SDXL-Lightning also offers a distilled LoRA version, compatible with other SDXL base models. Those interested might want to give it a try.
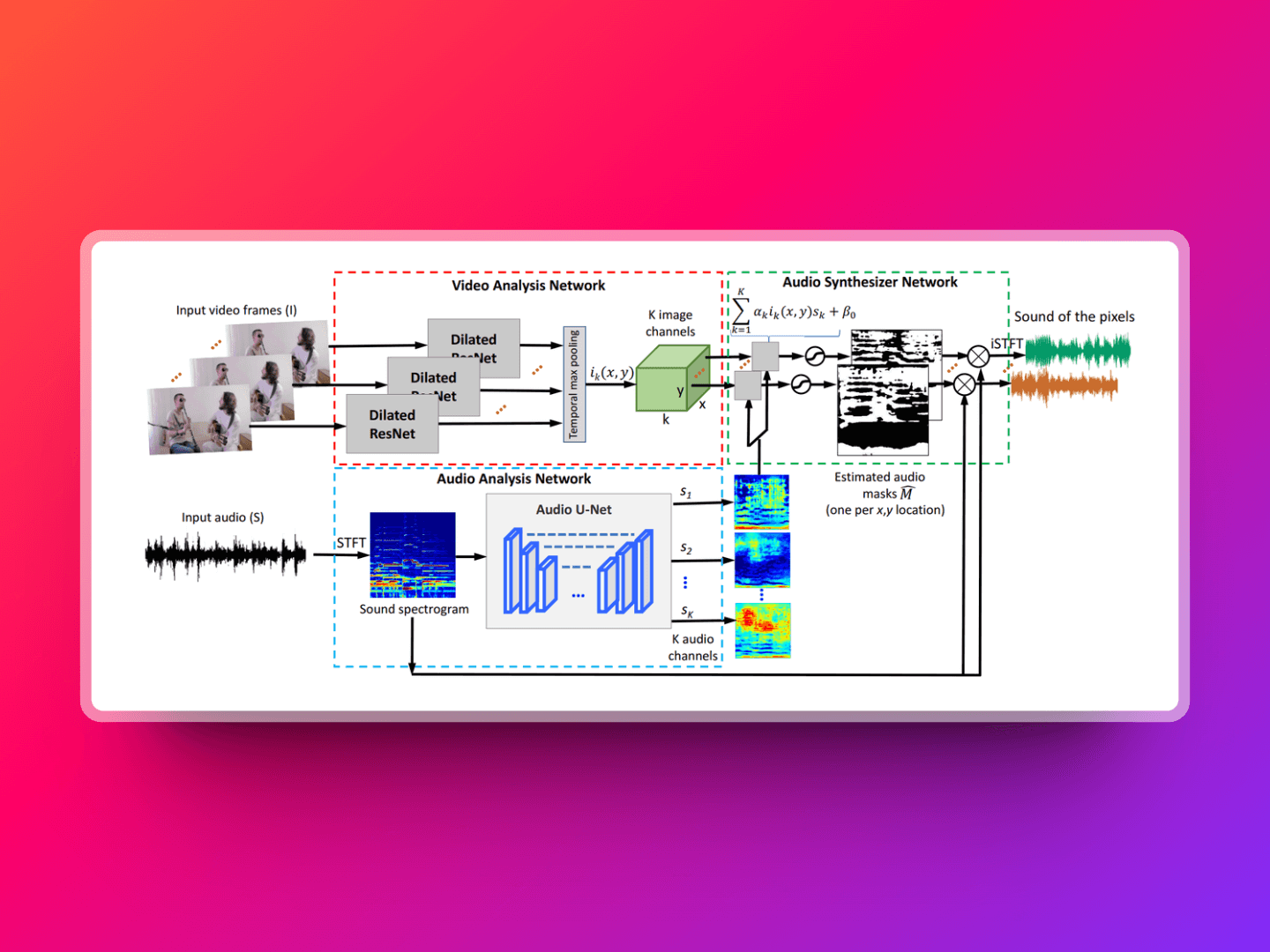
This is a project developed by the MIT research team that can automatically identify and separate different sound sources from videos and match them with their locations in the footage. For example, it can recognize which character is speaking or which instrument is being played in the video. Moreover, it can extract and separate these sound sources individually. PixelPlayer is capable of self-learning and analysis without the need for manually labeled data. This capability provides a powerful tool for audio-video editing, multimedia content creation, augmented reality applications, and more, making it possible to independently adjust the volume of different sound sources in a video, remove or enhance specific sound sources, etc.
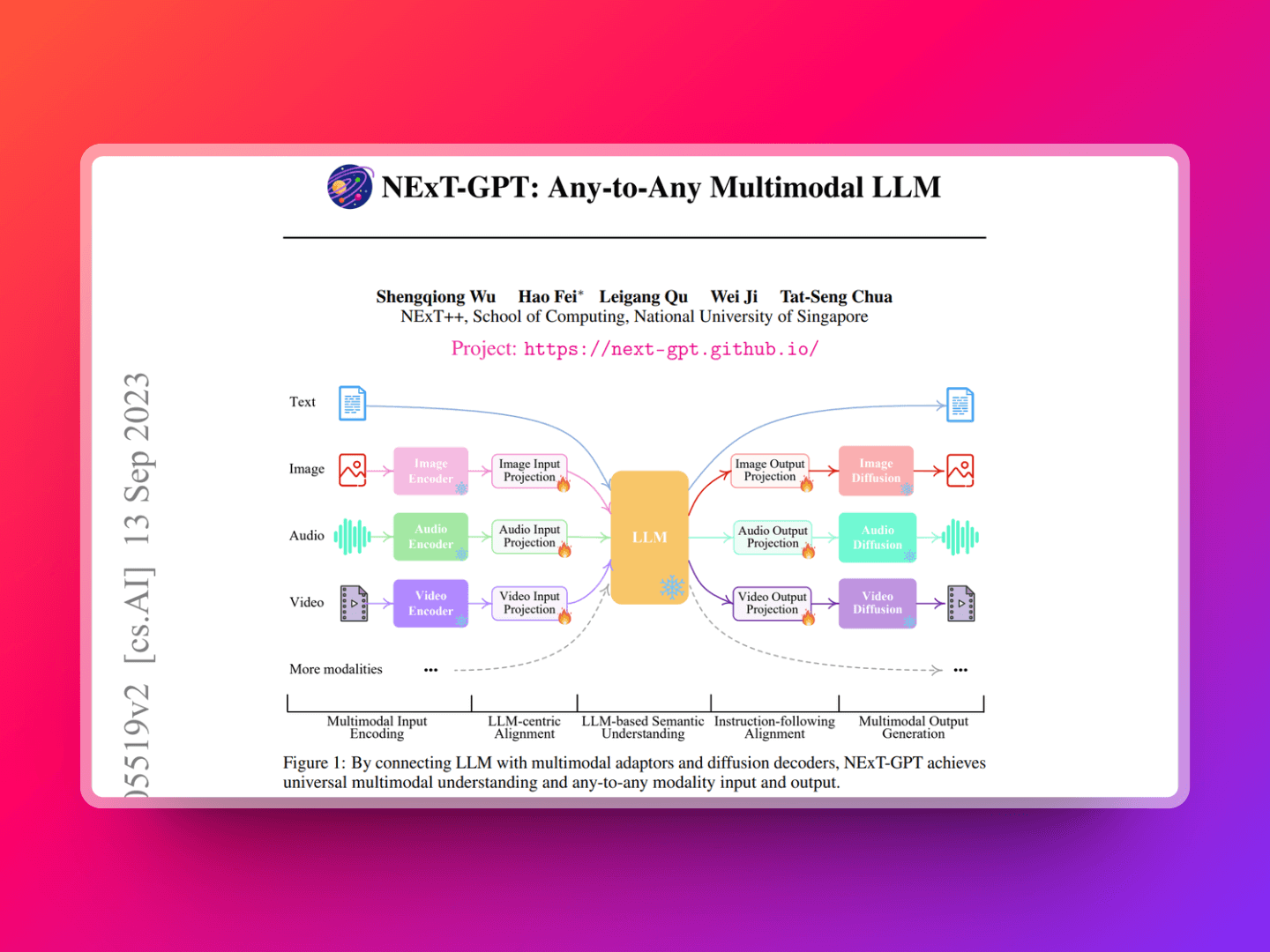
AnyGPT is an innovative multimodal language model that, through a process of discretization, transforms data from various modalities such as images, voice, and music into token sequences understandable by the language model. This approach enables AnyGPT to seamlessly transition between different modalities, thereby enhancing flexibility and efficiency in content understanding and generation. For example, it can convert a descriptive text into its corresponding image or generate lyrics based on a musical piece, capabilities that were previously challenging to achieve with language models.
YOLOv8 can quickly and accurately identify and locate multiple objects in images or video frames, track their movements, and classify them. In addition to detecting objects, YOLOv8 can also distinguish the exact contours of objects, perform instance segmentation, estimate human poses, and assist in recognizing and analyzing specific patterns in medical imaging, among other computer vision tasks.

🛠️ Products you should try
OpenAI launched the video generation mega-model Sora, which is capable of generating complex scenes with multiple characters, specific movements, and detailed themes and backgrounds. This model not only understands the requirements specified in the prompts by the users but also comprehends how these requirements can be realized in the physical world. Sora employs diffusion models to refine complex, abstract fragments until a clear image is formed. Moreover, it utilizes the Transformer architecture to process continuous video frames, making the movements in the video (such as the blooming of flowers or the movement of sunlight) appear smooth and natural.

Google has released two open-source LLM (Large Language Model) models of different weight scales: Gemma 2B (2 billion parameters) and Gemma 7B (7 billion parameters). These models share technology and infrastructure with Google's largest and most capable AI model, Gemini. Each size offers versions that are pre-trained and fine-tuned with instructions, and the terms of use allow all organizations, regardless of size, to responsibly commercialize and distribute them.
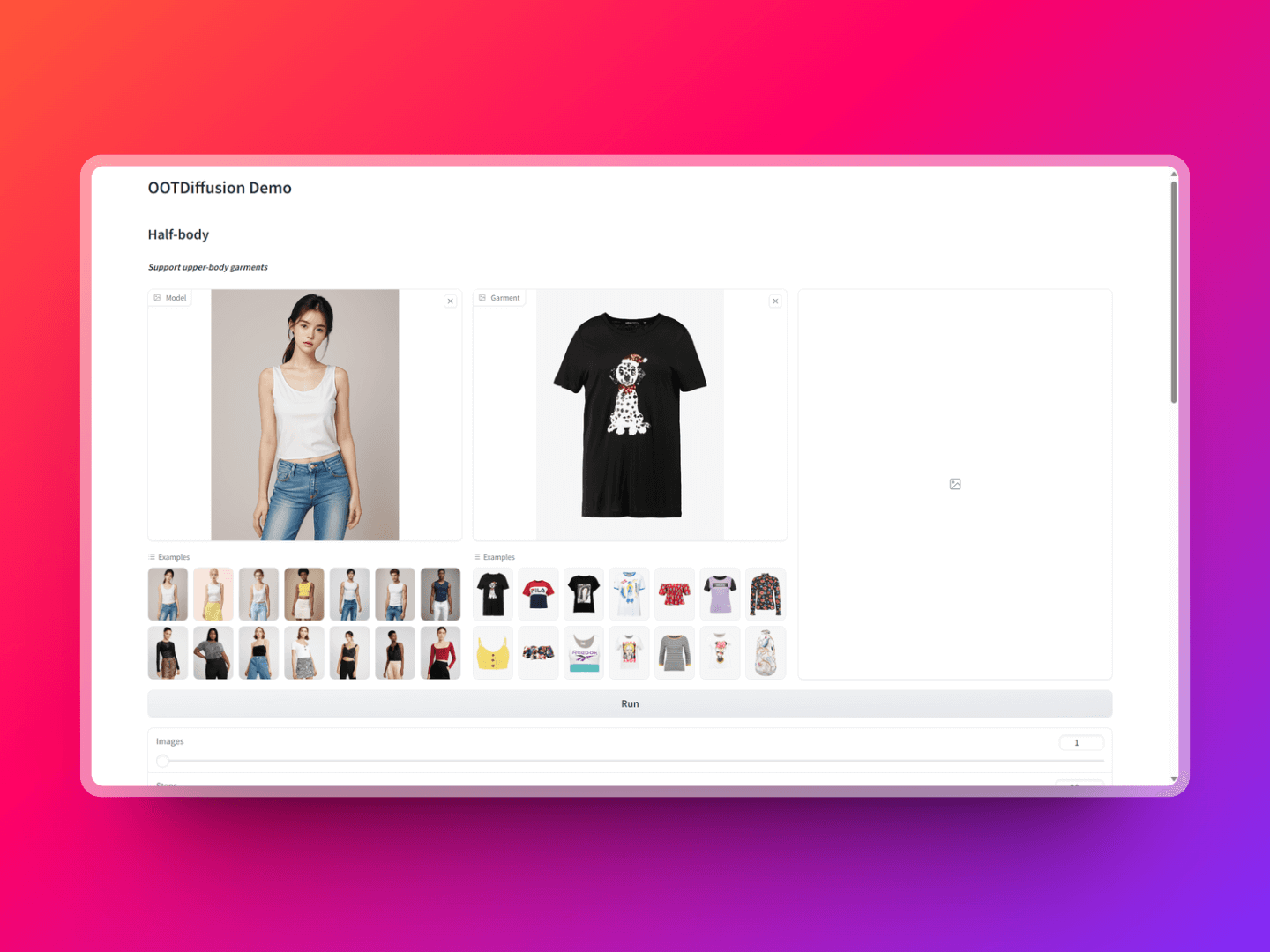
OOTDiffusion is a virtual try-on technology based on latent diffusion, primarily aimed at enabling users to try on different outfits in a virtual environment through controlled outfit blending. This technology integrates the latest machine learning algorithms with image processing techniques, offering users a novel virtual try-on experience. This open-source tool supports both half-body and full-body models and allows adjustments to the try-on effects based on individual needs and preferences, ensuring a close fit between the clothing effect images and the model. Those interested might want to give it a try.