AI Weekly 020
🆕 What's New?
New blog: Comflowy Cloud FAQ (opens in a new tab)
Download link: Comflowyspace (opens in a new tab)
Weekly‘s AI highlights
🪐Workflow worth trying
IMAGE TO JADE STYLE (opens in a new tab)
This is a workflow capable of generating a jade-like texture, especially performing well in traditional Chinese-style illustrations and portrait photos.

Manga Cosplay (opens in a new tab)
This is a workflow that can use real photos to generate cartoon-style illustrations, primarily utilizing InstantID and BRIA RMBG to remove the background. However, it is only suitable for single-person scenarios, as it replaces only one face. If you want to use it for multi-person scenarios, you can disable the faceswap module.

You can subscribe to our newsletter (opens in a new tab), or join our Discord (opens in a new tab) to get the latest tutorials.
🏗️Plugins worth trying
ComfyUI-Gemini (opens in a new tab)
This plugin supports the latest Gemini 1.5 Pro model, allowing users to execute system command settings, multimodal and multi-turn dialogues, and process text, image, video, and audio files with a size limit of 20GB. It also offers high token support, enabling it to handle long text inputs.

ComfyUI-IC-Light-Native (opens in a new tab)
IC-Light is an open-source project capable of generating lighting effects in images. It provides two models: text-conditioned relighting and background-conditioned relighting, allowing users to control the lighting and ambiance of an image through simple prompts.
📄 Noteworthy papers and technic
AniTalker (opens in a new tab)
AniTalker can transform a single static portrait and input audio into an animated conversation video with natural, fluid motions. It's like bringing the person in the photo to life, making them move in sync with the audio. The lip movements match the speech, and the facial expressions and head movements appear very natural, just like a real person talking.

Vidu is a high-performance text-to-video generator capable of creating up to 16 seconds of 1080p video in a single generation. It is a diffusion model based on U-ViT, capable of producing realistic and imaginative videos. It also understands some professional photography techniques, as demonstrated in the image below, where it can control the direction and movement of light sources within the scene.

MistoLine (opens in a new tab)
MistoLine can generate high-quality images directly from hand-drawn sketches that match the contours of the sketches. It is an SDXL-ControINet-based model that can be used in ComfyUI. By utilizing various line drawings provided by the user (including hand-drawn sketches, line drawings generated by different preprocessors, and outlines automatically generated by the model), it achieves flexible adaptation to different types of sketches and high-precision image generation.

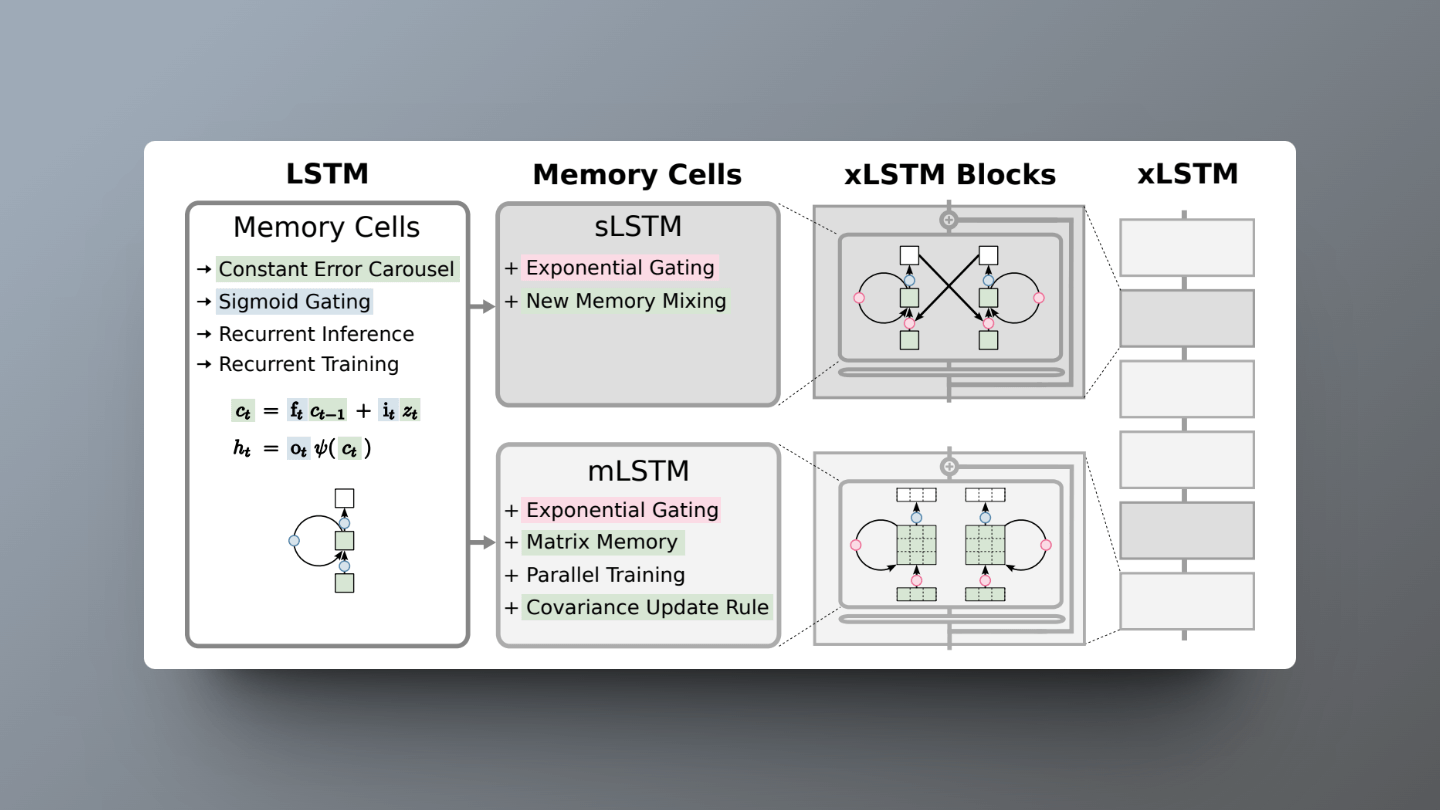
xLSTM is an upgrade to the original LSTM (Long Short-Term Memory) network. LSTM is a highly effective tool for handling sequential data, such as language and time series prediction. However, when dealing with very large datasets, LSTM can struggle. xLSTM addresses these issues by introducing exponential gating and modifying the LSTM memory structure.
Lumina-T2X (opens in a new tab)
Lumina-T2X can convert text descriptions into high-definition images, videos, 3D models, and audio. Using specialized techniques to process text, it can generate high-resolution and arbitrarily sized multimodal content. In simple terms, if you can describe it, Lumina-T2X can create the corresponding visual or audio content based on your description. Compared to OpenAI's DALL-E, Lumina-T2X can handle multimodal content generation, including text-to-image tasks, while excelling in high-resolution image capabilities. Its model architecture and scale also surpass some versions of DALL-E or GPT-3.

🛠️ Products you should try
The newly launched Stylar product claims to be the most controllable AI image and design tool. It combines generative AI and editing tools on a single platform, offering various style libraries and combination tools. Users can complete all operations from image generation to editing through modifying natural language instructions, enabling customized image design.

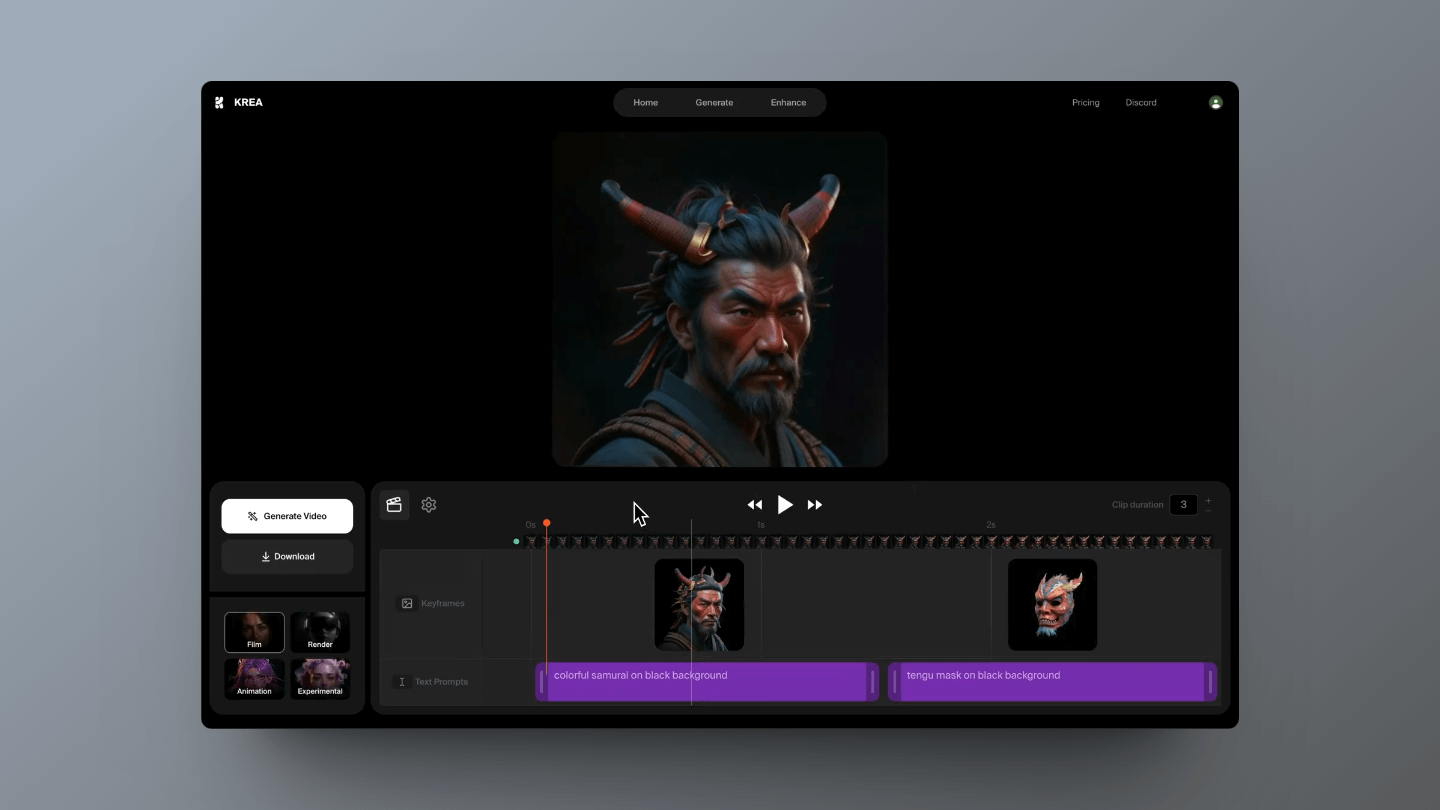
Krea Video (opens in a new tab)
Krea Video is Krea's latest AI-generated video feature that allows users to create videos using keyframes and text prompts. Users can flexibly move and adjust video content on the timeline, achieving diverse visual effects and storytelling methods. Compared to other video editing tools, Krea Video's keyframe feature enables users to precisely control the visual effects and content style at different points in time, ensuring that every frame of the video meets creative and brand requirements.
Ilus AI is an AI illustration generator capable of quickly producing illustrations in various styles, including ink drawings, doodles, and flat designs. Users can select preset illustration styles and generate illustrations automatically by inputting keywords, or they can upload their own illustration samples to train a personalized AI model. The generated illustrations can be exported in SVG and PNG formats, making them convenient for use in different applications.

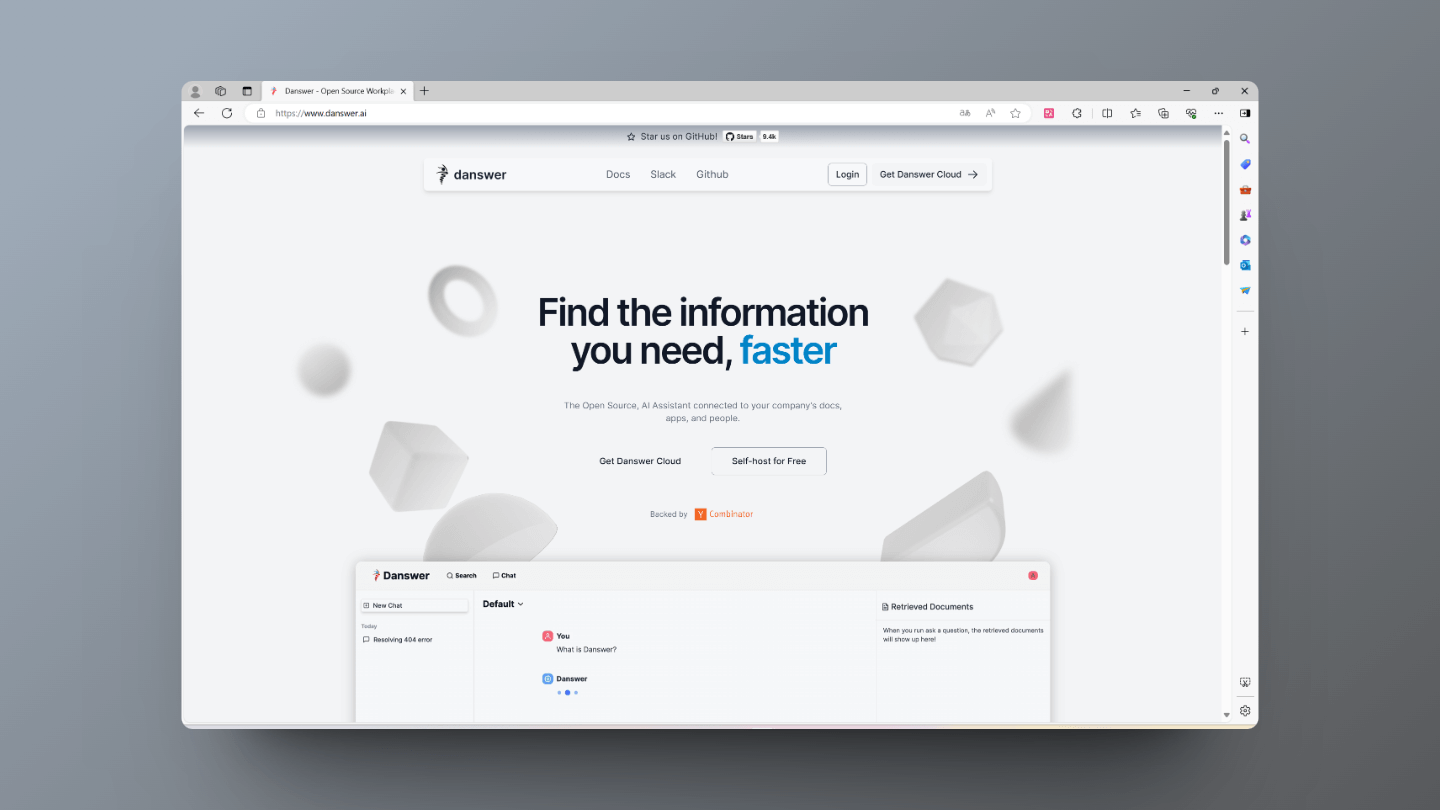
Danswer is an open-source AI assistant designed specifically for enterprise environments. It can quickly connect to a company's documents, applications, and personnel, leveraging the internal knowledge base to provide AI-driven answers based on real sources. It also offers over 25 plug-and-play integration options, supports various large model providers, and allows users to integrate their own self-hosted large language models (LLMs). Additionally, this product has received investment from Y Combinator (YC).