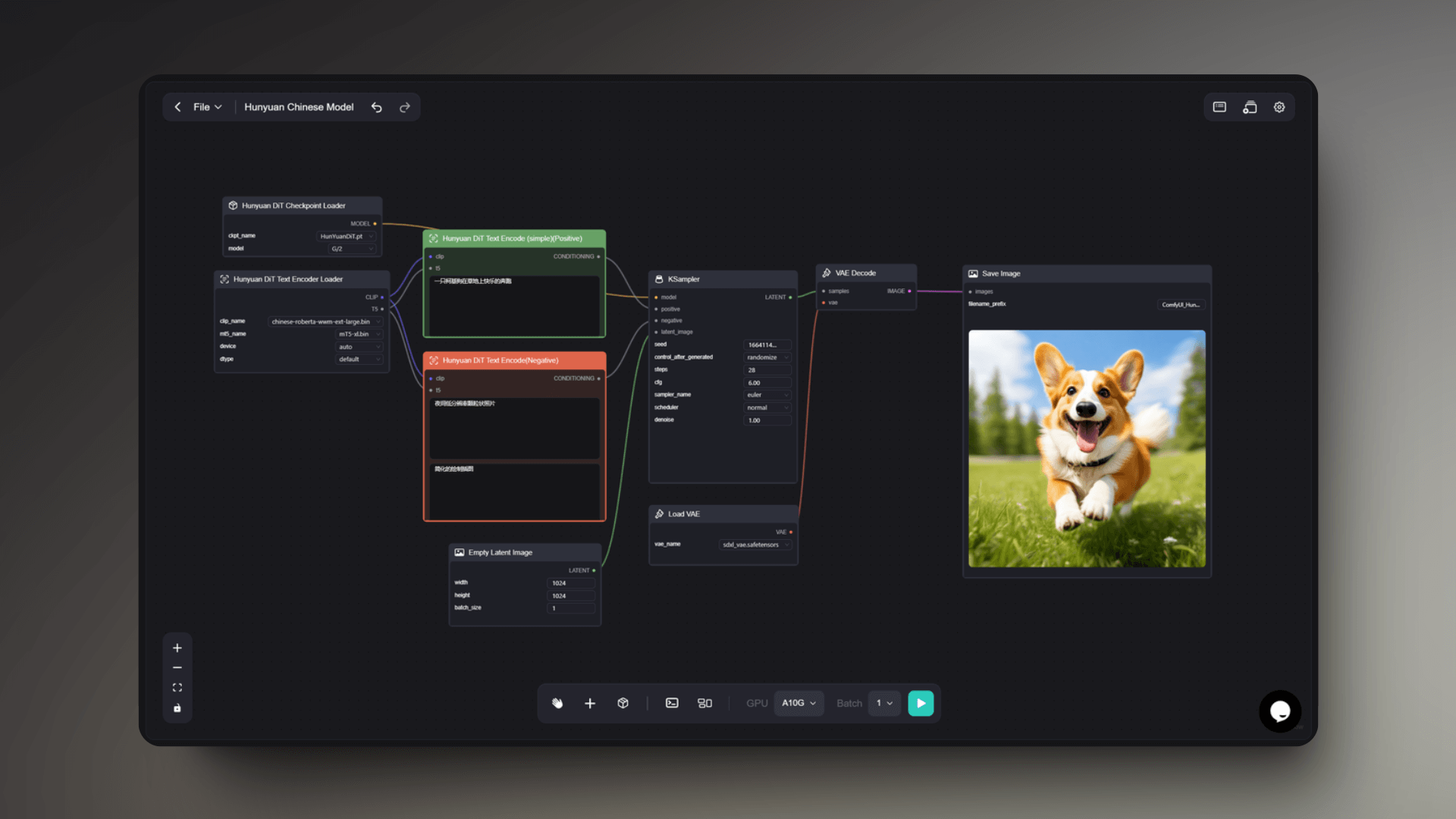
Lumina Long Photo & Hunyuan Chinese Model
Lumina Long Photo
This workflow primarily utilizes the Lumina model to generate long images. The Lumina model can comprehend the structure of long images, breaking them down into multiple independent parts or "blocks." Each block can be controlled by prompt words to achieve independent generation. Finally, this workflow will synthesize these different contents into a long image with a unified style and harmonious visual experience, maintaining overall consistency and coordination.
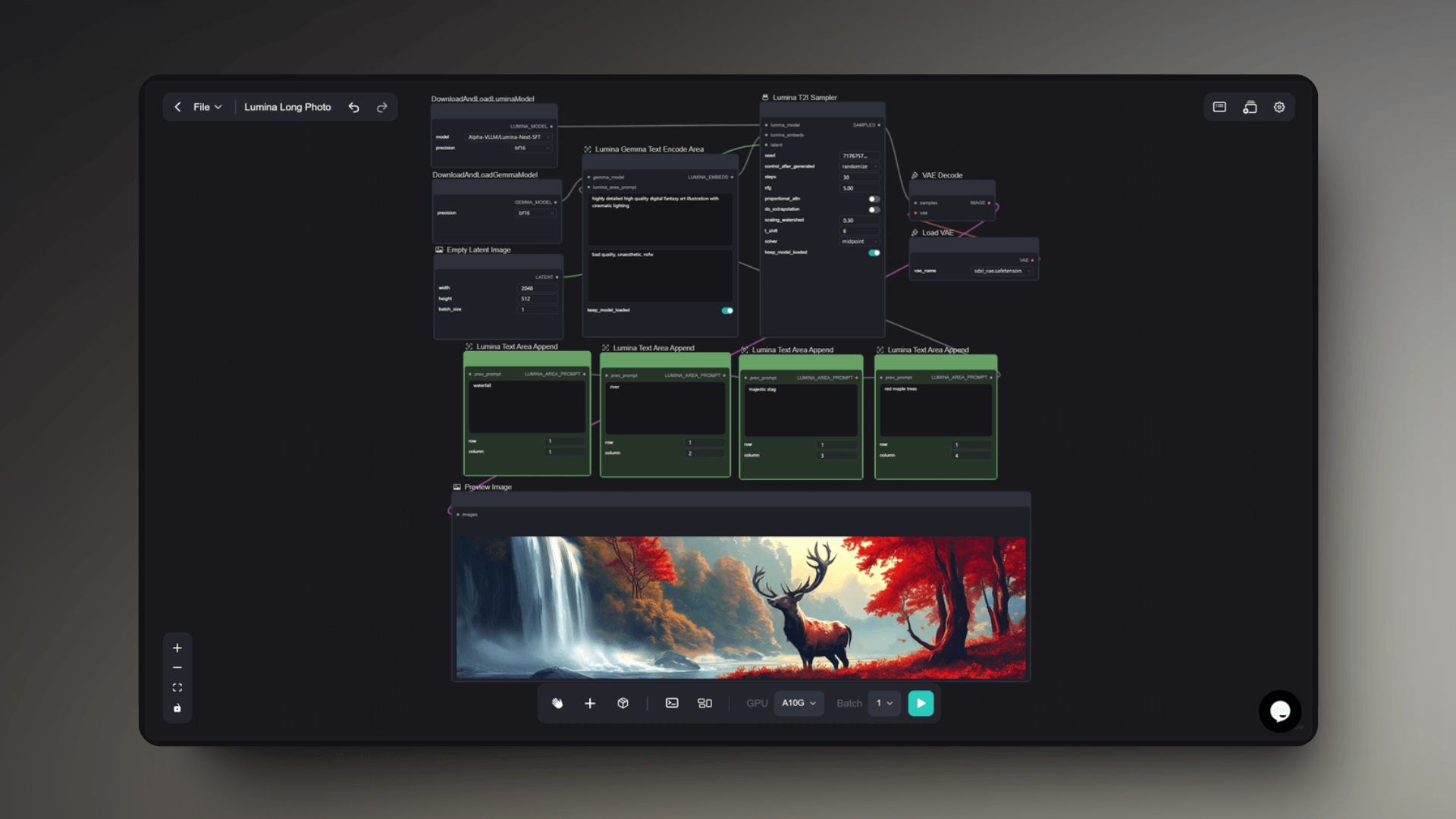
For example, in the image above, we can divide this long image into four parts, and control the generation of each part from left to right as: waterfall, river, majestic deer, and red maple tree. It can be seen that the final generated effect is consistent with the content input by the prompt words.

Game Scene
Before generating a game scene, we often need to plan the overall layout and style of the scene. For example, selecting the type of scene (such as castles, forests, dungeons, etc.), as well as determining the atmosphere and theme of the scene. The Lumina model can generate scenes with specific terrain features based on the prompt words you provide, such as rugged mountains, flat grasslands, or winding rivers, and can also generate natural elements such as trees, shrubs, and flowers, or specify architectural styles, such as Gothic, modern, or futurism.

Game scenes are not just visual; they also carry the functions of narrative and emotional guidance. Designers guide players' emotions and the progression of the story through scene layout and element design. At this time, a series of prompt words can be provided to guide the Lumina model in generating the content of each block. These prompt words can include colors, styles, themes, elements, etc., to ensure that the generated images meet one's expectations.

Although each block is generated independently, the Lumina model ensures that all blocks maintain consistency in style and visual aspects, including color tones, textures, and lighting effects, to achieve visual harmony. Once all blocks have been generated, the workflow will automatically stitch them together to form a complete long image. During the synthesis process, the model will adjust the edges and transitions to ensure there are no obvious seams or discordant areas.

Describing Dreams
Everyone's dreams are unique. With personalized prompt words, the Lumina model can generate images that reflect the user's personal dreams. Often, our memories of dreams are not entirely clear, and we might only remember a few things that appeared. In such cases, you can input these key elements as prompt words to generate dream scenes.

It can even reflect the user's emotional state, such as happiness, sadness, or fear. Prompt words can include emotional keywords to help the model capture and express these emotions.

Dreams often include abstract and surreal elements. With the Lumina model, users can generate images that cannot be explained by traditional logic, such as floating islands, warped spaces, or dreamy colors.

Hunyuan Chinese Model
For Chinese users, using Chinese prompt words to run the workflow is a more efficient and intuitive method. This workflow can support the expression of one's creativity and ideas using Chinese prompt words to generate images.
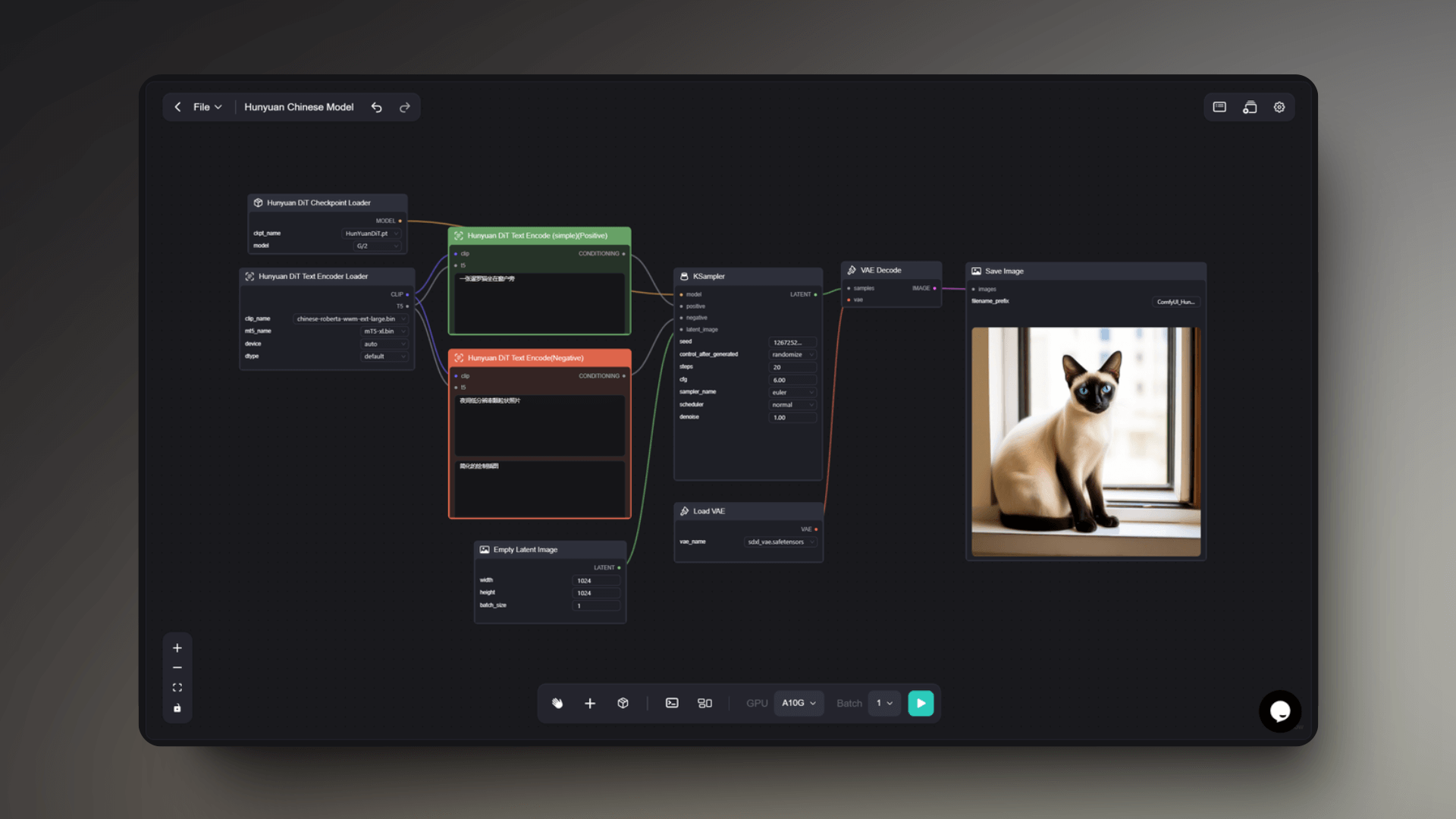
You can use simple sentences, idioms, verses, or any form of Chinese description as prompt words, and the workflow can recognize and respond accordingly.
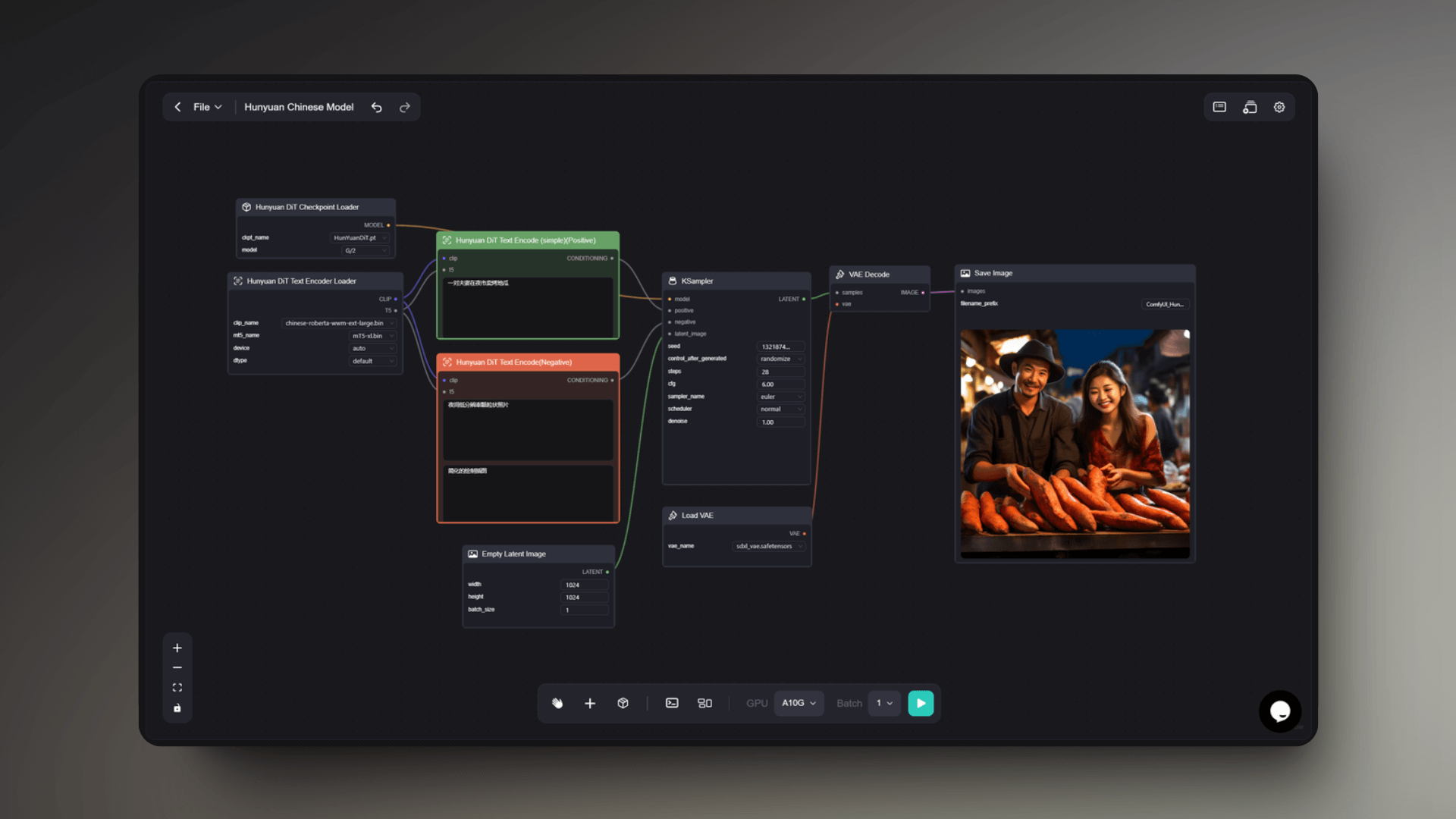
This workflow has a strong scene-building capability. Users can describe a scene with Chinese prompt words, and the workflow can understand the composition elements of the scene to generate images with a sense of space and narrative, such as: a couple selling roasted sweet potatoes at a night market, a girl reading in the library, an old man resting in the park, and so on.
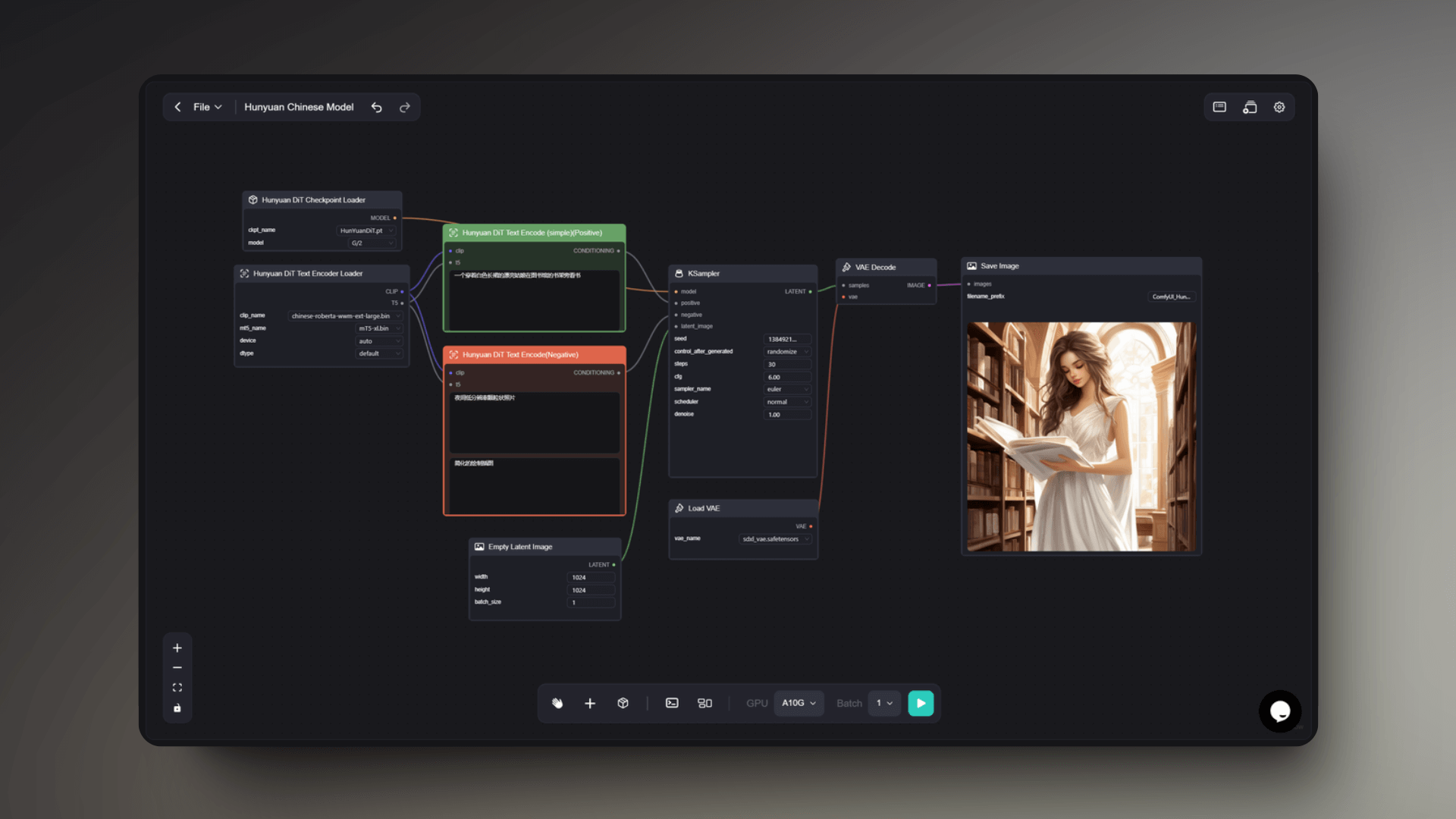
It can render the appropriate environmental atmosphere according to the descriptions in the prompt words, such as the liveliness of the night market, the tranquility of the library, and the leisureliness of the park. For the characters in the scene, it can also capture their age, gender, clothing, expressions, and other characteristics, and depict them in detail in the image.
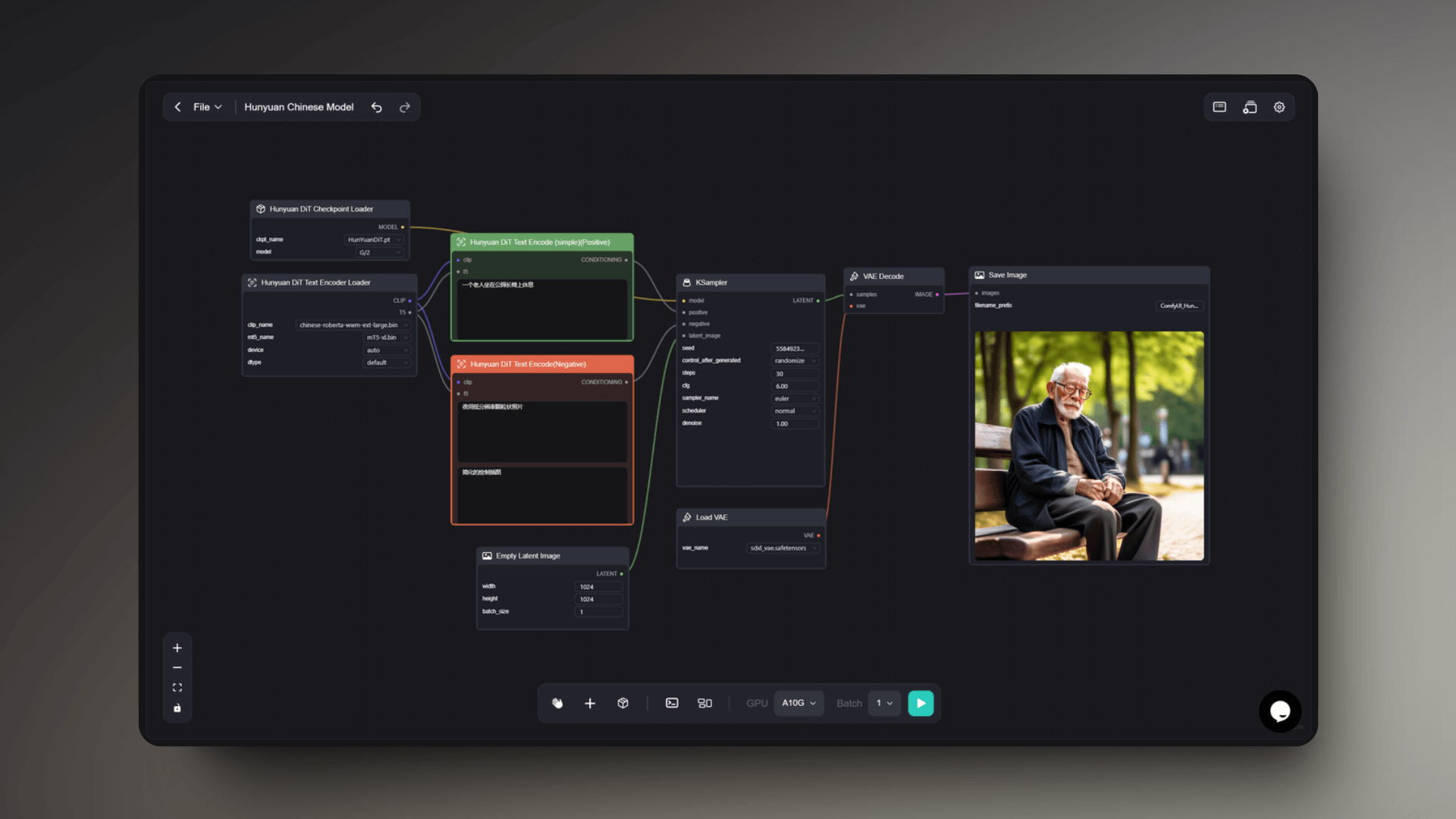
It can also simulate different lighting conditions, such as the lights at night, the soft light indoors, etc., to enhance the realism and three-dimensionality of the image. In the generated scene images, the workflow will add rich details, such as the stalls at the night market, the bookshelves in the library, the benches in the park, etc., making the scene more vivid.