IPAdapter Tutorial
1. Introduction
ComfyUI IPAdapter Plugin is a tool that can easily achieve image-to-image transformation. It is akin to a single-image Lora technique, capable of applying the style or theme of one reference image to another. Through this image-to-image conditional transformation, it facilitates the easy transfer of styles and themes. Compared to text-to-image generation, existing text-to-image diffusion models can create high-fidelity images, but generating the desired image solely from textual prompts often requires complex prompt engineering. Image prompts serve as an alternative, expressing more content and details than text.
2. Installation Steps
-
To use the IPAdapter plugin, you need to ensure that your computer has the latest version of ComfyUI and the plugin installed.
-
To install the insightface dependency, if you are unsure how to install dependencies, you can watch the video: Comflowy FAQ (opens in a new tab).
-
The IPAdapter node supports a variety of different models, such as SD1.5, SDXL, etc., each with its own strengths and applicable scenarios. Additionally, IPAdapter Plus specifically supports the corresponding FaceID model for style transfer on human figures. You can use it to control the facial features of a person to ensure consistency with the original image. You can find detailed steps for installation and the differences between models in this article: How to perform style transfer using IPAdapter Plus in ComfyUI? (opens in a new tab)
3. Technical Principles
The core technology of IPAdapter lies in its innovative decoupled cross-attention mechanism. In standard text-to-image diffusion models, the cross-attention layers are primarily optimized for text features, which limits the model's ability to finely process image features. To overcome this limitation, IPAdapter introduces a dedicated image feature cross-attention layer that works in parallel with the original text feature cross-attention layer, capturing and integrating image features to ensure that the detailed information of the image is fully preserved and utilized.
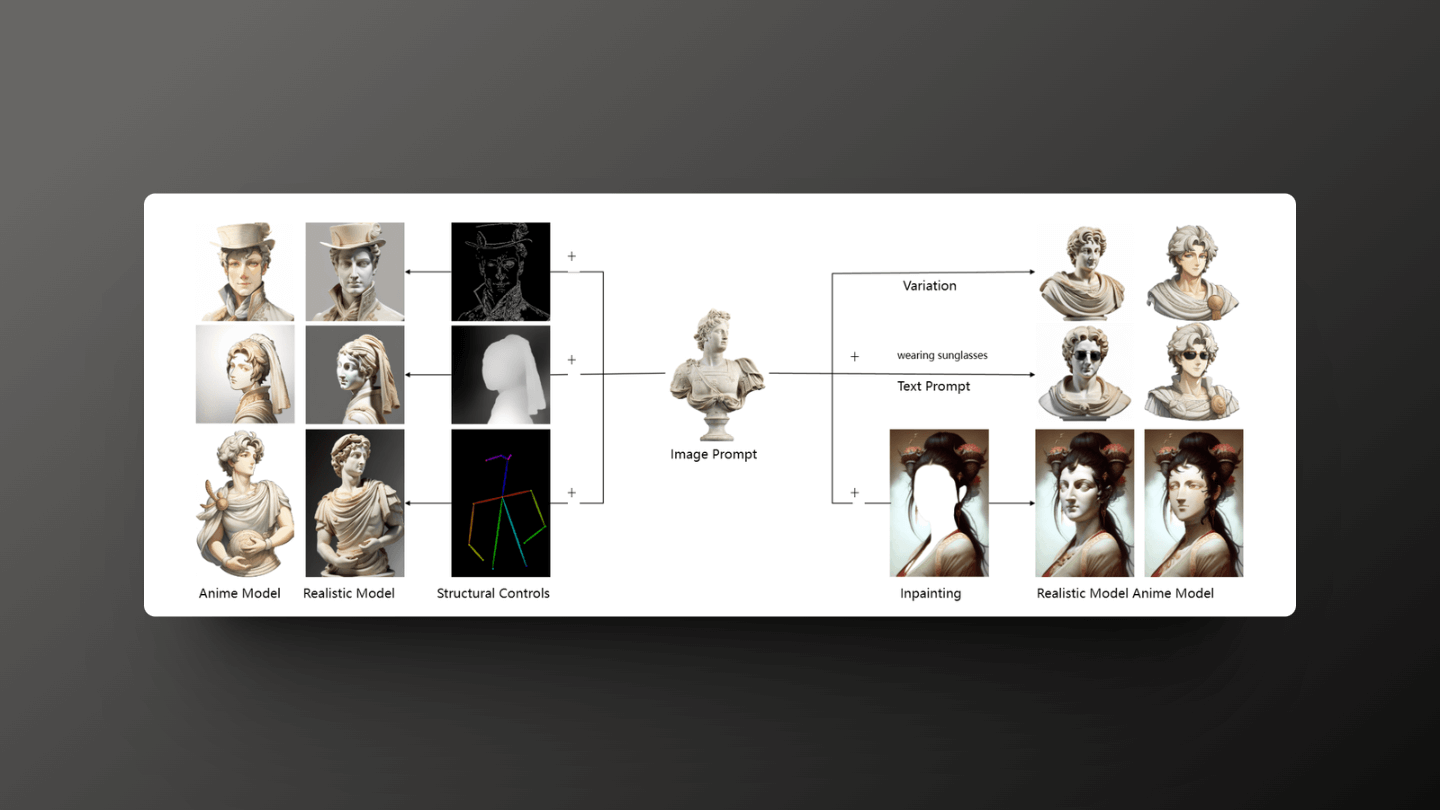
Additionally, ControlNet Reference-only can implement image variants on the SD model without the need for training by simply injecting features. Uni-ControlNet's global control adapter can project image embeddings from the CLIP image encoder into conditional embeddings using a small network, and connect them with the original text embeddings, guiding the generation of style and content of the reference image.
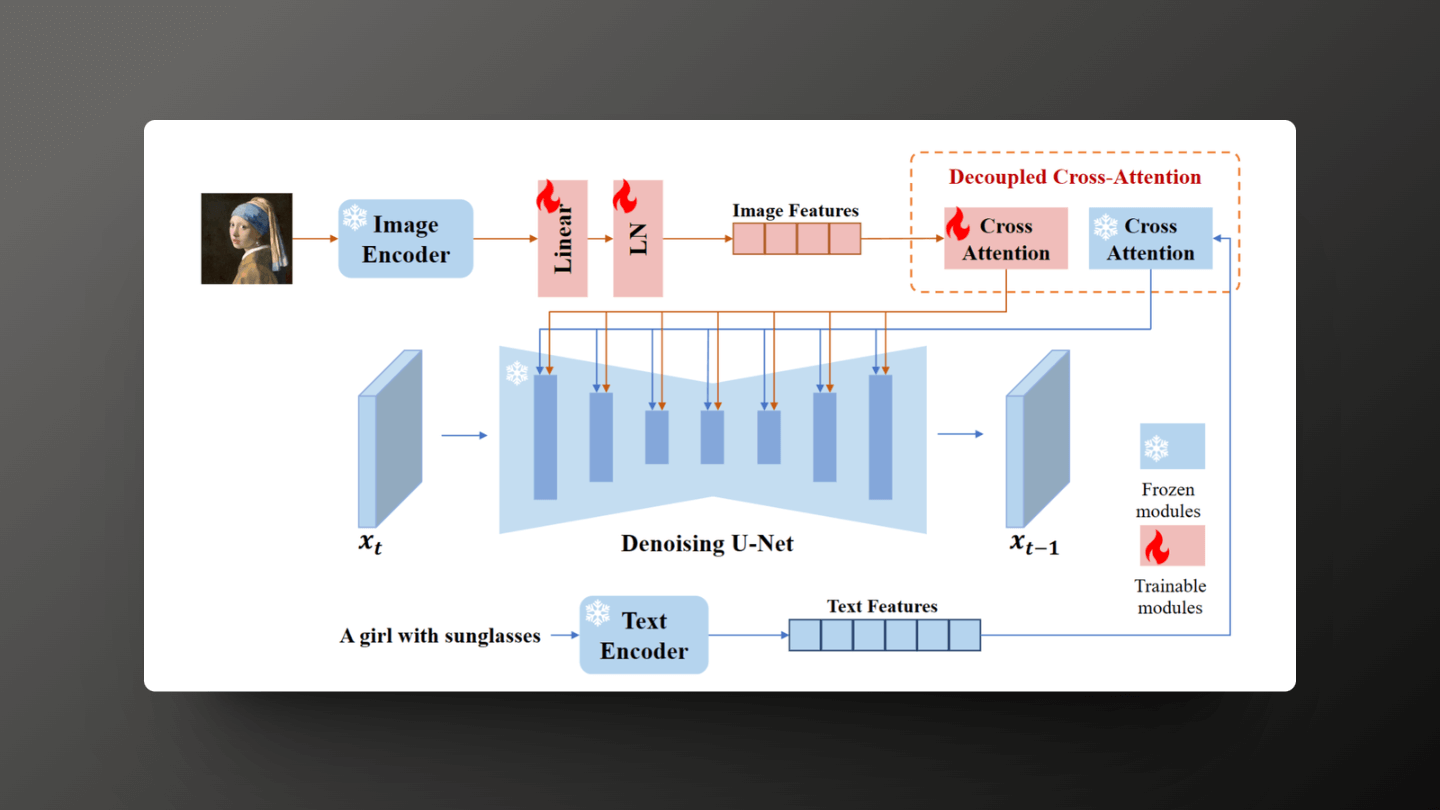
If you want to gain a detailed understanding of IPAdapter, you can refer to the paper:IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models (opens in a new tab)
4. Node Introduction
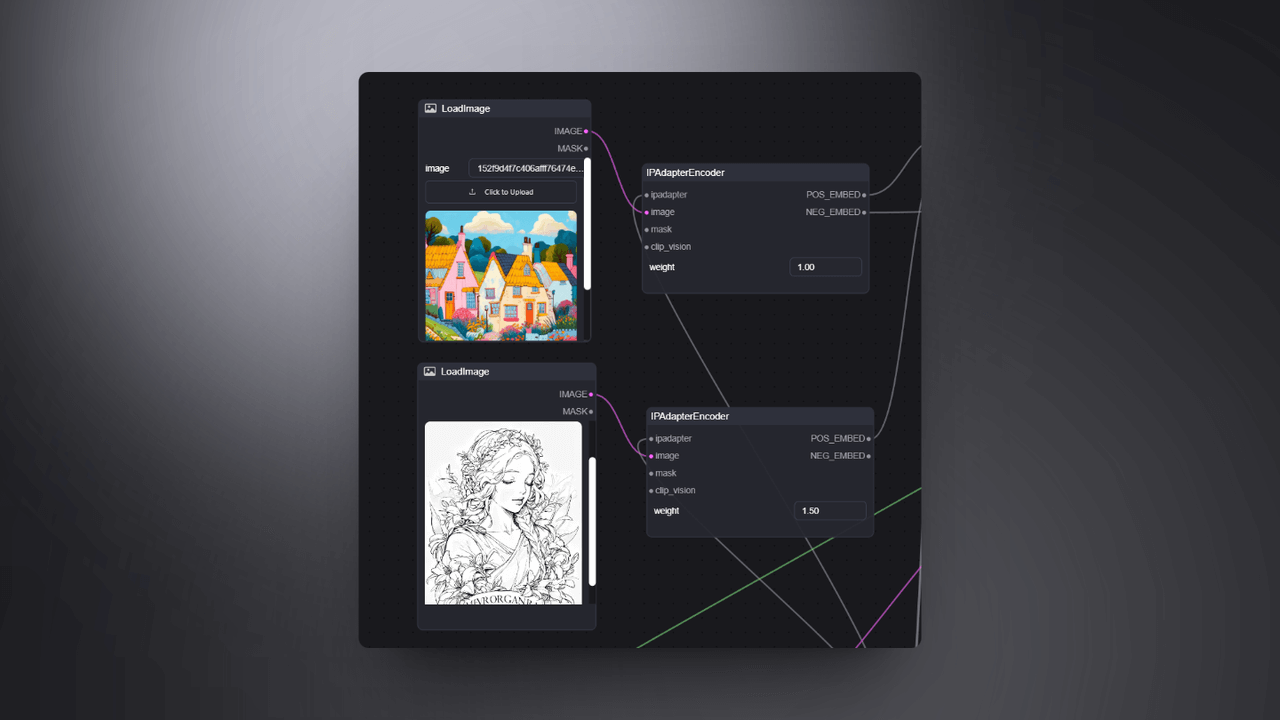
4.1 IPAdapterEncoder
The IPAdapterEncoder node's primary function is to encode the input image or image features. It receives the original image and captures the important features and information of the image, which can then be used for image-to-image transformation, style transfer, or other more complex image processing tasks. In this scenario, we connect this node to both the original and reference images, with the original image having a weight of 1 and the reference image having a weight of 1.5. This allows us to have greater control over the reference image, enabling the generation of images with the same posture and stylistic features as the reference image in subsequent processes.
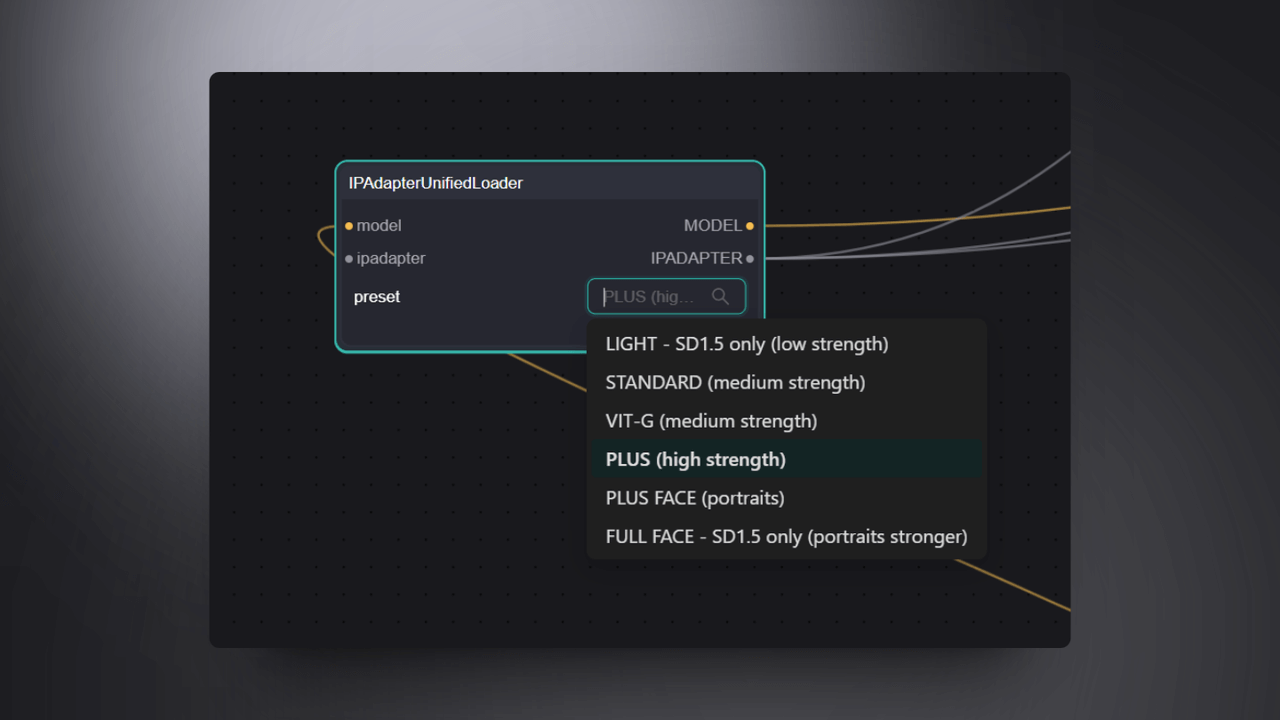
4.2 IPAdapterUnifiedLoader
The IPAdapterUnifiedLoader node is responsible for loading the pre-trained IPAdapter models. This node provides a unified interface for loading various IPAdapter models, including basic models, enhanced models, facial models, and so on. Through this node, users can easily select and load the required models without the need to manually download and configure files. Here, I have chosen the Plus (high strength) option.
4.3 IPAdapterCombineEmbeds:
The IPAdapterCombineEmbeds node functions to merge multiple encoded image embeddings into a single unified embedding representation. In image-to-image transformation tasks, this can be used to combine features from different images, such as extracting style and content from various images and integrating them into the generated image. This combination can produce new visual effects while preserving important visual elements from the original images.
4.4 IPAdapterEmbeds:
The IPAdapterEmbeds node is used for generating image embeddings. It takes encoded image data as input and outputs an embedding vector that captures the key features of the image. This can be utilized for subsequent image generation or editing tasks, such as altering the style or content of the generated image by adjusting certain dimensions of the embedding vector.
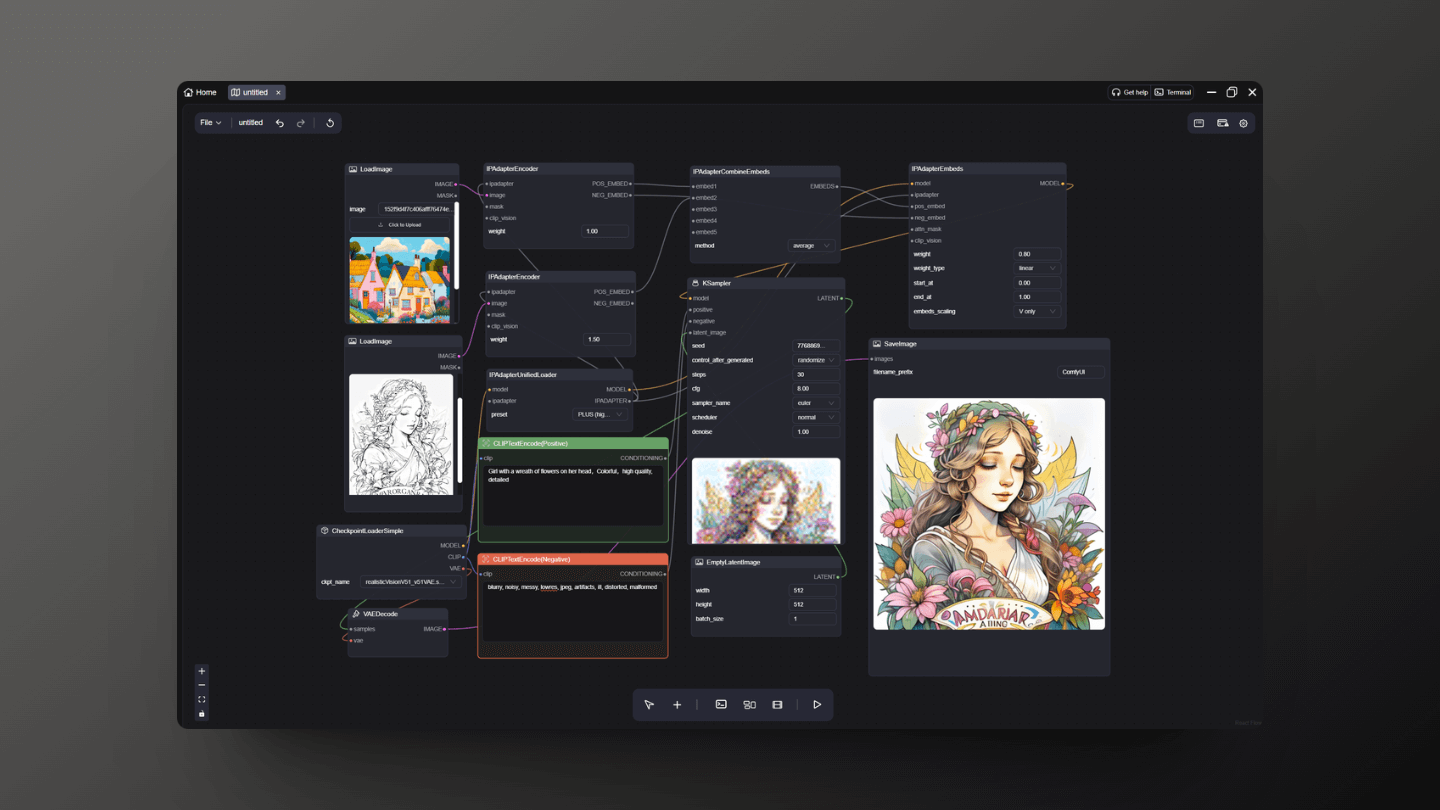
5. IPAdapter Plugin Functions and Uses
5.1 Style Transfer:
IPAdapter can capture the style and theme of a reference image and apply it to newly generated images. This allows users to control the extent of style transfer by adjusting the weight parameters of the node, creating images that maintain visual consistency with the reference image in terms of style.
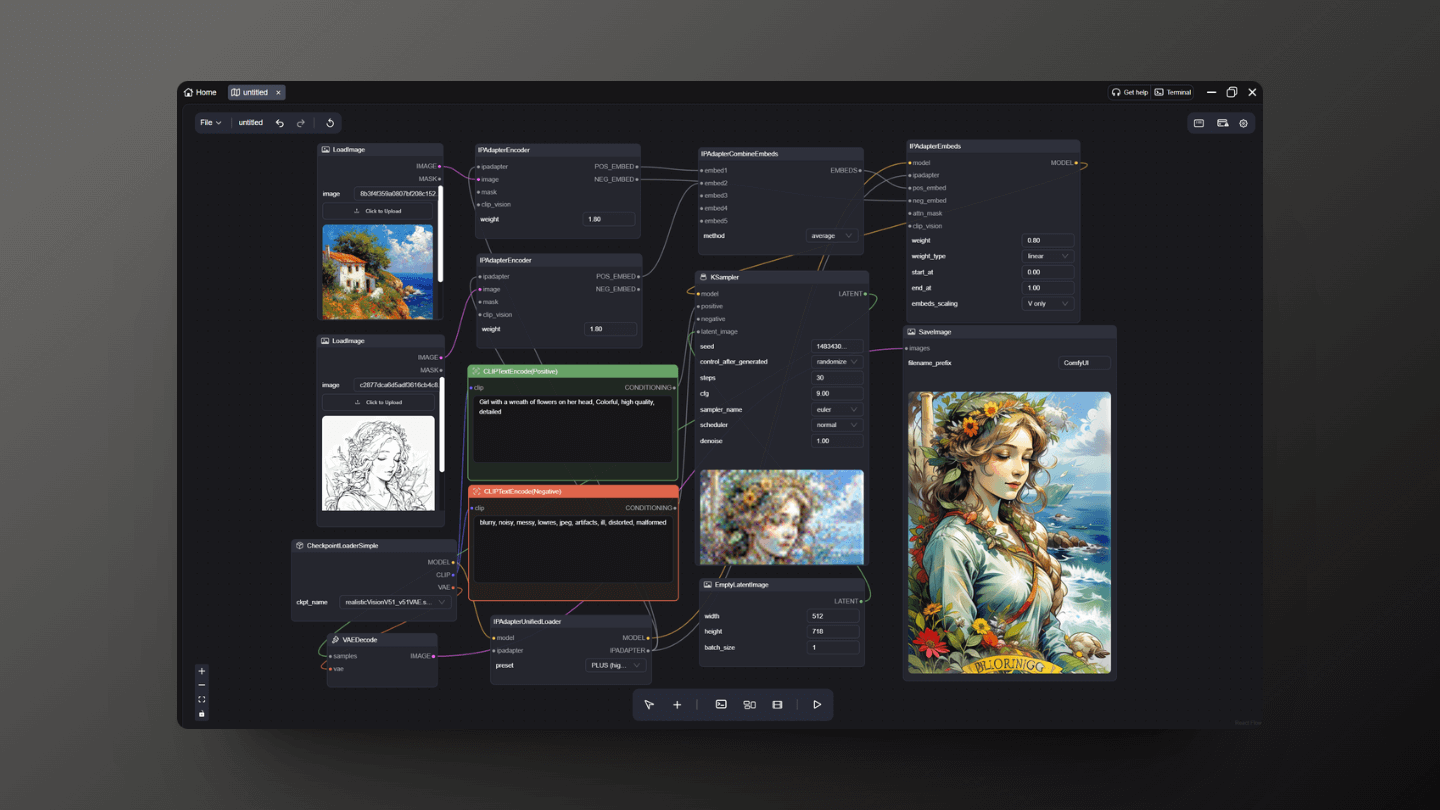
You can control the intensity of style or content transformation by adjusting the weight parameters. Different weight values produce different transformation effects, meeting various creative needs. Additionally, increasing the number of iterations can improve image quality, but it will also increase computation time, which can be adjusted according to your requirements.
5.2 Content Transformation:
In addition to style, the IPAdapter node can also handle content transformation or fusion of images. For example, it can recognize and analyze facial features and apply these characteristics to other images, generating new images with similar facial traits.
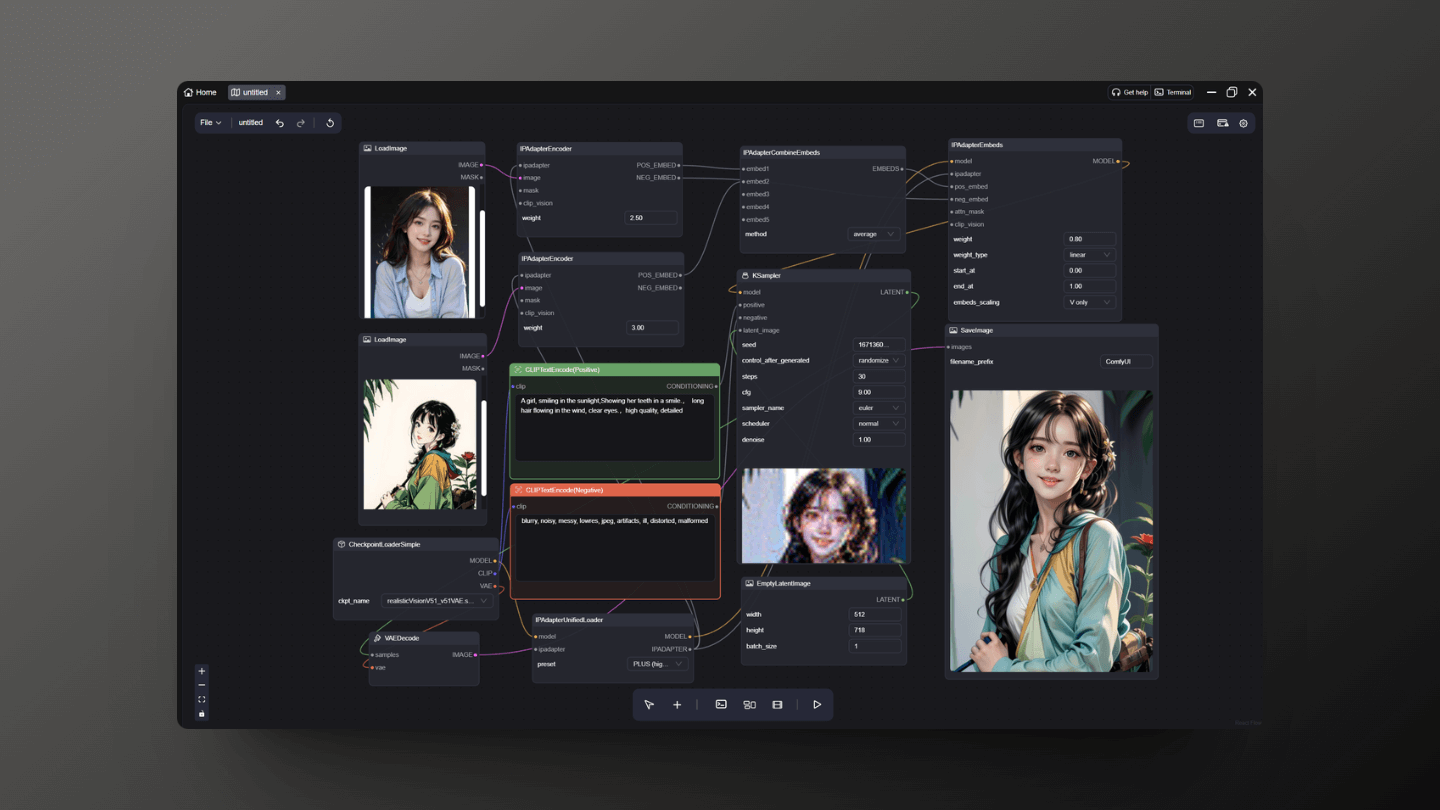
This kind of facial feature transformation demonstrates its unique value in fields such as portrait creation, character design, and face synthesis. With this approach, it is possible to create images with a high degree of consistency and personalized features without starting from scratch with drawing or design.
5.3 Conditional Generation
IPAdapter allows users to generate new images based on specific input conditions. These conditions can be textual descriptions, another image, or a combination of both. With this capability for conditional generation, users can create customized images that match the provided conditions.
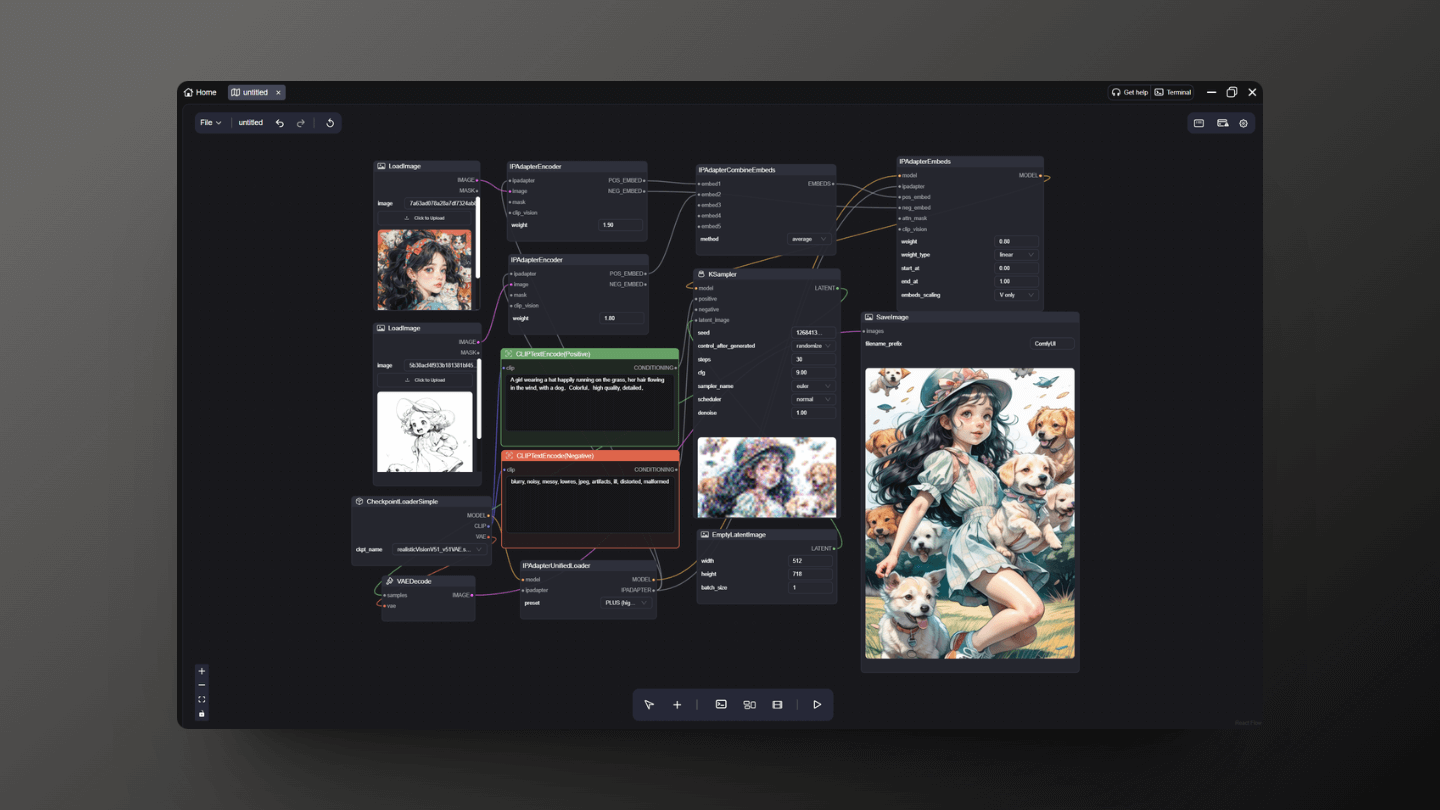
-
Text Description: You can input text descriptions, and the plugin will parse these descriptions to generate images based on their content. This is particularly useful for creating visual content based on textual descriptions, such as bringing a scene or character to life from a description.
-
Image Condition: You can also provide a reference image as a condition, and the plugin will analyze the content and style of this image to generate a new image that is similar to it. This is very useful when you need to create variations or extensions based on an existing image.
-
Combination of Text and Image: A more advanced use is the combination of text descriptions and a reference image. In this case, the plugin will take into account both the content of the text description and the style of the reference image to generate a new image that meets the description and has the style of the reference image.

5.4 Animation Support:
The IPAdapter plugin supports the creation of animations, greatly simplifying the process of creating dynamic image sequences with the feature of adding preset weights. Users can achieve smooth transitions and coherence in animations by finely adjusting the weights between frames, while independently controlling the style and content of each frame to ensure that every detail of the animation meets expectations.
The plugin's smooth transition feature ensures that animations remain natural and fluid even when there are significant changes in weights. The loop animation option allows for the creation of seamless looping visual effects. The real-time preview and adjustment functions increase the efficiency of animation production, enabling users to quickly iterate and perfect their work. In addition, the IPAdapter plugin supports a variety of models, including facial and SDXL models, providing users with a broad range of creative options for generating high-quality animation frames.
6. 6. Workflow Introduction
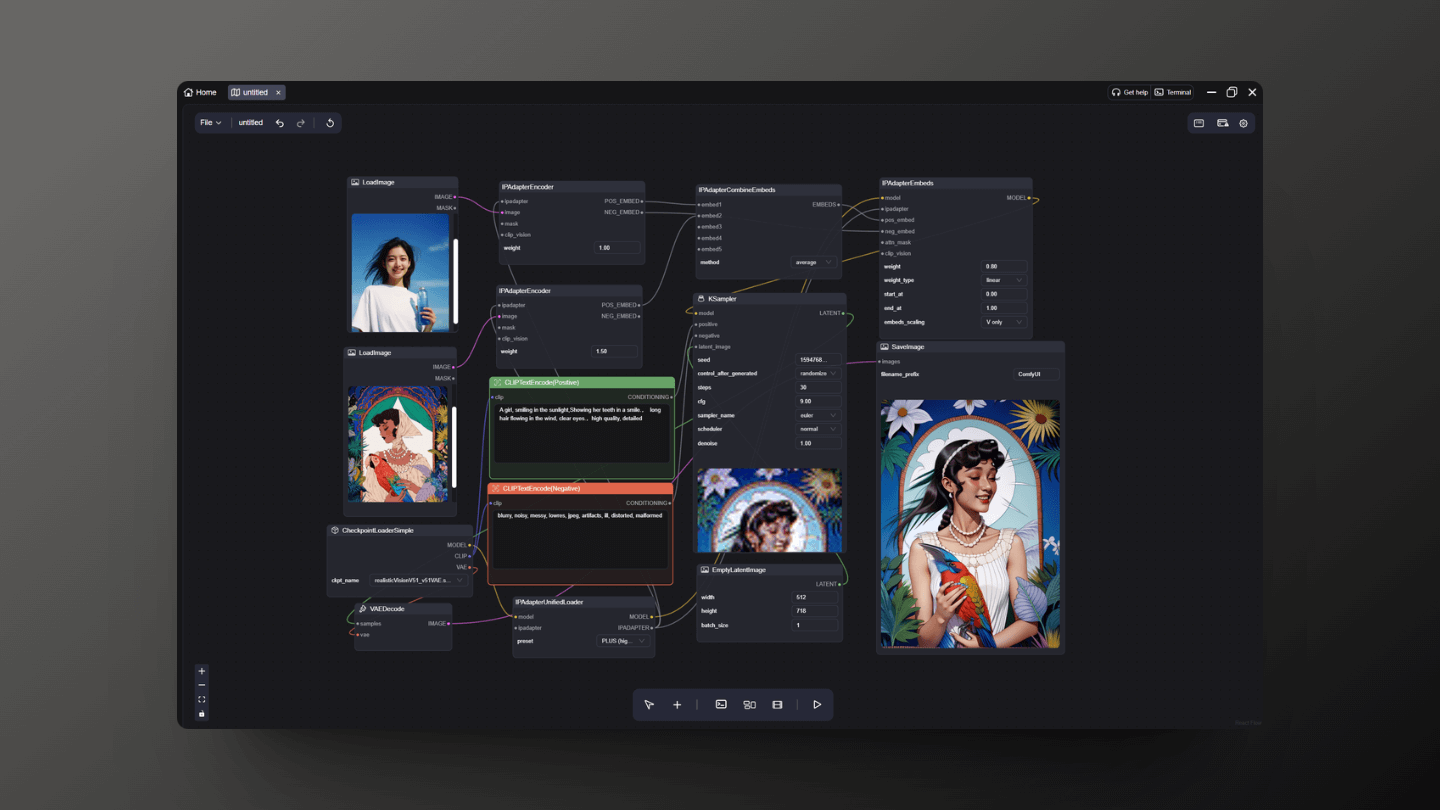
6.1 Style Transfer
This workflow fully supports you in completing style transfer. You can find it in the example files of the node package on Github, or you can refer to the image examples to set it up yourself.
Note: Two IPAdapterEmbeds nodes are respectively controlling the input image and the reference image; you can control which image's style will be more dominant in the final output by increasing the weight value.
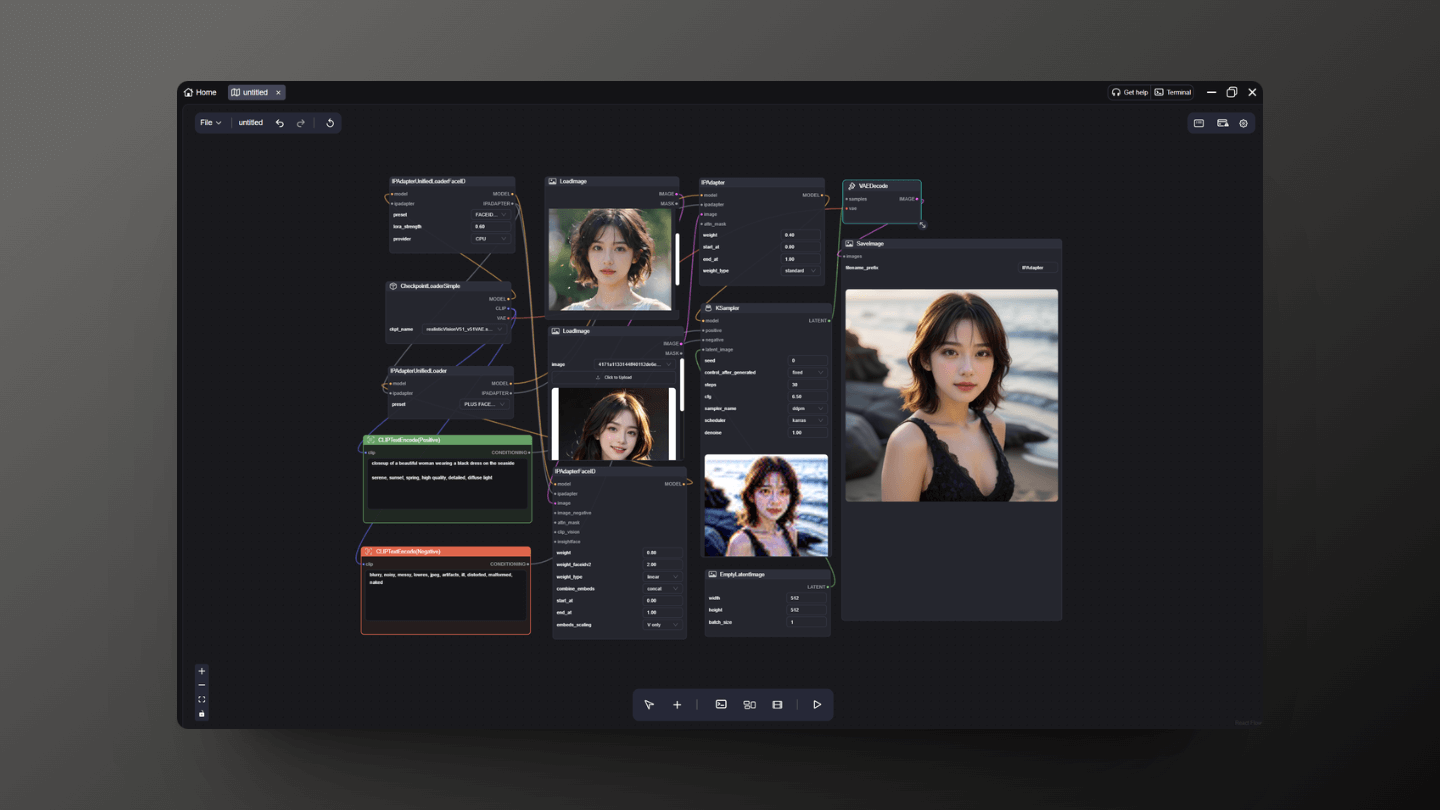
6.2 FaceID
FaceID has more powerful capabilities for handling facial details. You need to add the IPAdapterUnifiedLoaderFaceID and IPAdapterFaceID nodes for use, and select the Face model you have downloaded within the IPAdapterUnifiedLoaderFaceID.
Finally, remember to switch the model in the IPAdapterUnifiedLoader to the one I am using here, which is PLUS FACE (portraits).
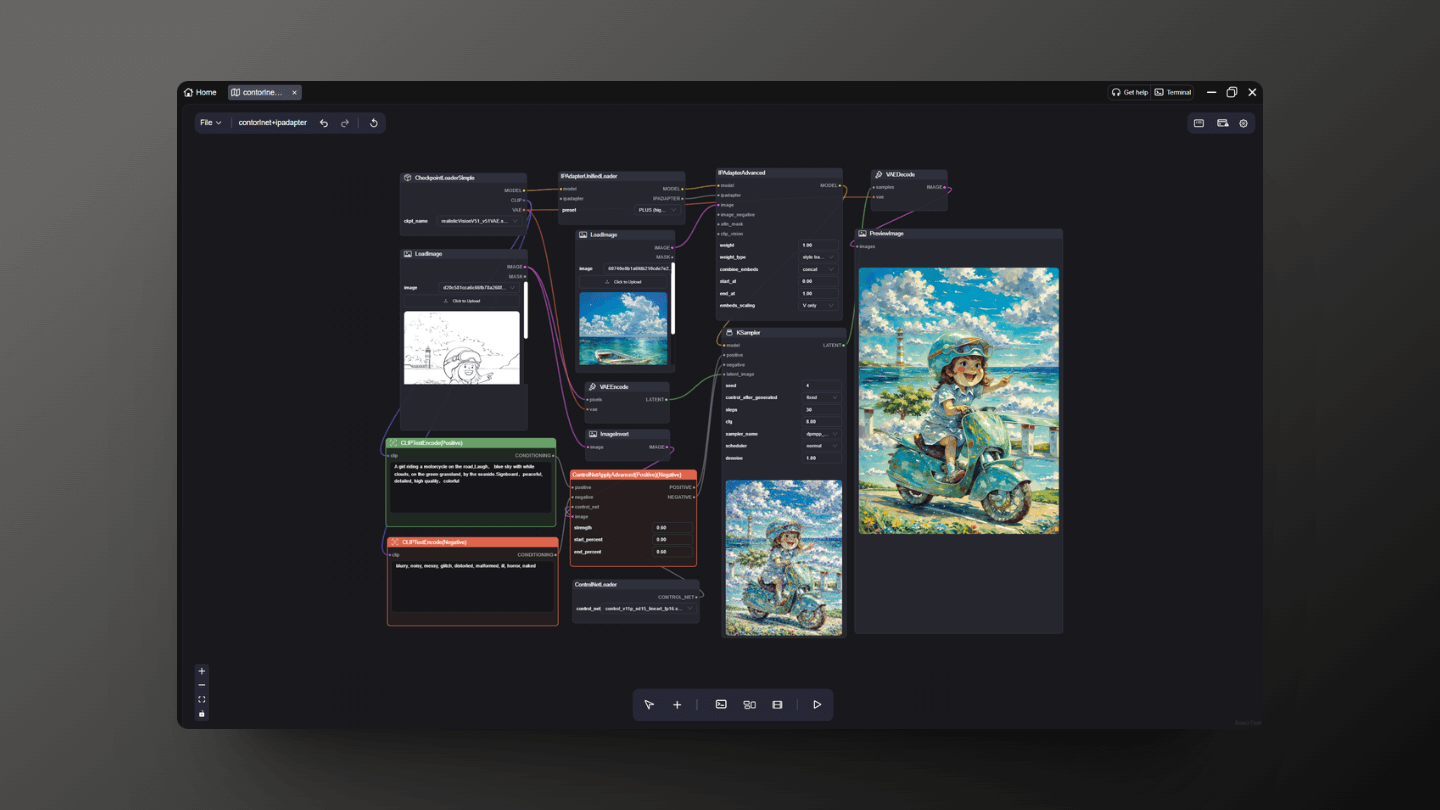
7. ContorlNet
If you want the final rendering to have a stronger correlation with the input image, the workflow mentioned above may not be sufficient. In this case, I recommend adding a ControlNet node to control the main subject's outline while performing style transfer.
For example, add the Controlnet lineart node to control the line drawing, ensuring that the final generated outline is consistent with the uploaded one. You just need to select your preferred reference image for upload, and you can transfer the color and texture of the reference image to the line drawing. By adjusting the steps and cfg, you can generate the desired effect. Here, I have set the steps to 30 and cfg to 8.
In addition to this, you can also generate specific poses by inputting a reference image, for which you might use the openpose model of Controlnet. The principle provided by the official source is shown in the following diagram, where you can alter the input person's image to any pose you desire.
