SD3
The highly anticipated Stable Diffusion 3 is finally open to the public. Specifically, the model released is Stable Diffusion 3 Medium, featuring 2 billion parameters. Its compact size and low hardware requirements enable it to run effortlessly on ordinary laptops. As Stability AI's most advanced open-source model for text-to-image generation, SD3 demonstrates significant improvements in image quality, text content generation, nuanced prompt understanding, and resource efficiency. Today, we will delve into the features of SD3 and how to utilize it within ComfyUI.

SD3 Model Pros and Cons
Key Advantages of SD3 Model:
-
Enhanced Image Quality: Overall improvement in image quality, capable of generating photo-realistic images with detailed textures, vibrant colors, and natural lighting. It can adapt flexibly to various styles without fine-tuning, generating stylized images such as cartoons or thick paints solely from prompts. It features a 16-channel VAE for better representation of hand and facial details.
-
Ability to Understand Complex Natural Language Prompts: SD3 can interpret complex natural language prompts including spatial reasoning, composition elements, pose actions, and style descriptions. Even with intricate instructions like "The first bottle is blue with the label '1.5', the second bottle is red labeled 'SDXL', and the third bottle is green labeled 'SD3'", SD3 can accurately generate corresponding images, with text accuracy surpassing that of Midjourney.

- Through the Diffusion Transformer architecture, SD3 Medium achieves improved correctness and coherence in English text spelling and spacing.
SD3 Model Cons
-
The licensing scope of the SD3 Medium model is under an open non-commercial license, meaning the model cannot be used for commercial purposes without official permission.
-
Currently unable to generate Chinese text.
-
Despite significant improvements in image quality, details, understanding of prompts, and text content generation, SD3 still has some shortcomings. For example, errors may occur when generating hands, and serious distortions can occur when generating full-body characters.

SD3 Default Workflow
SD3 Model Download
Currently, three medium-sized parameter models are available for free download on HuggingFace, including:
-
sd3_medium.safetensors: Includes MMDiT and VAE weights but excludes any text encoder.
-
sd3_medium_incl_clips_t5xxlfp8.safetensors: Contains all necessary weights, including a fp8 version of the T5XXL text encoder, balancing quality and resource requirements.
-
sd3_medium_incl_clips.safetensors: Includes all necessary weights except for the T5XXL text encoder. It requires minimal resources, but the model's performance will differ without the T5XXL text encoder.
I have compared the incl clip models using the same prompts and parameters:
Prompt:Digital art, portrait of an anthropomorphic roaring Tiger warrior with full armor, close up in the middle of a battle, behind him there is a banner with the text "Open Source".

This is a basic workflow for SD3, which can generate text more accurately and improve overall image quality. However, it currently only supports English and does not support Chinese. It's important to note that the incl clip model is required here.
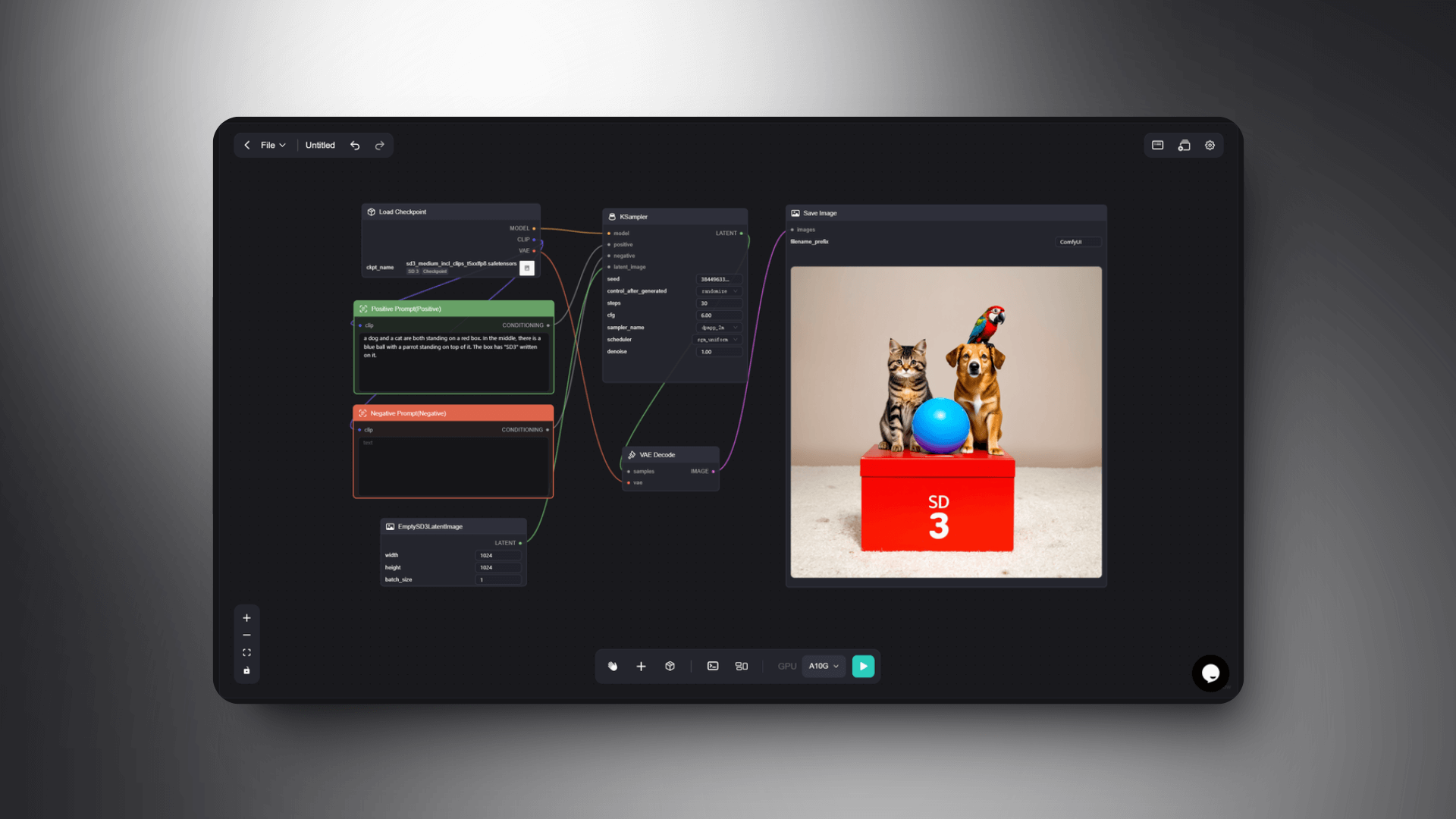
Prompt:a dog and a cat are both standing on a red box. In the middle, there is a blue ball with a parrot standing on top of it. The box has "SD3" written on it.
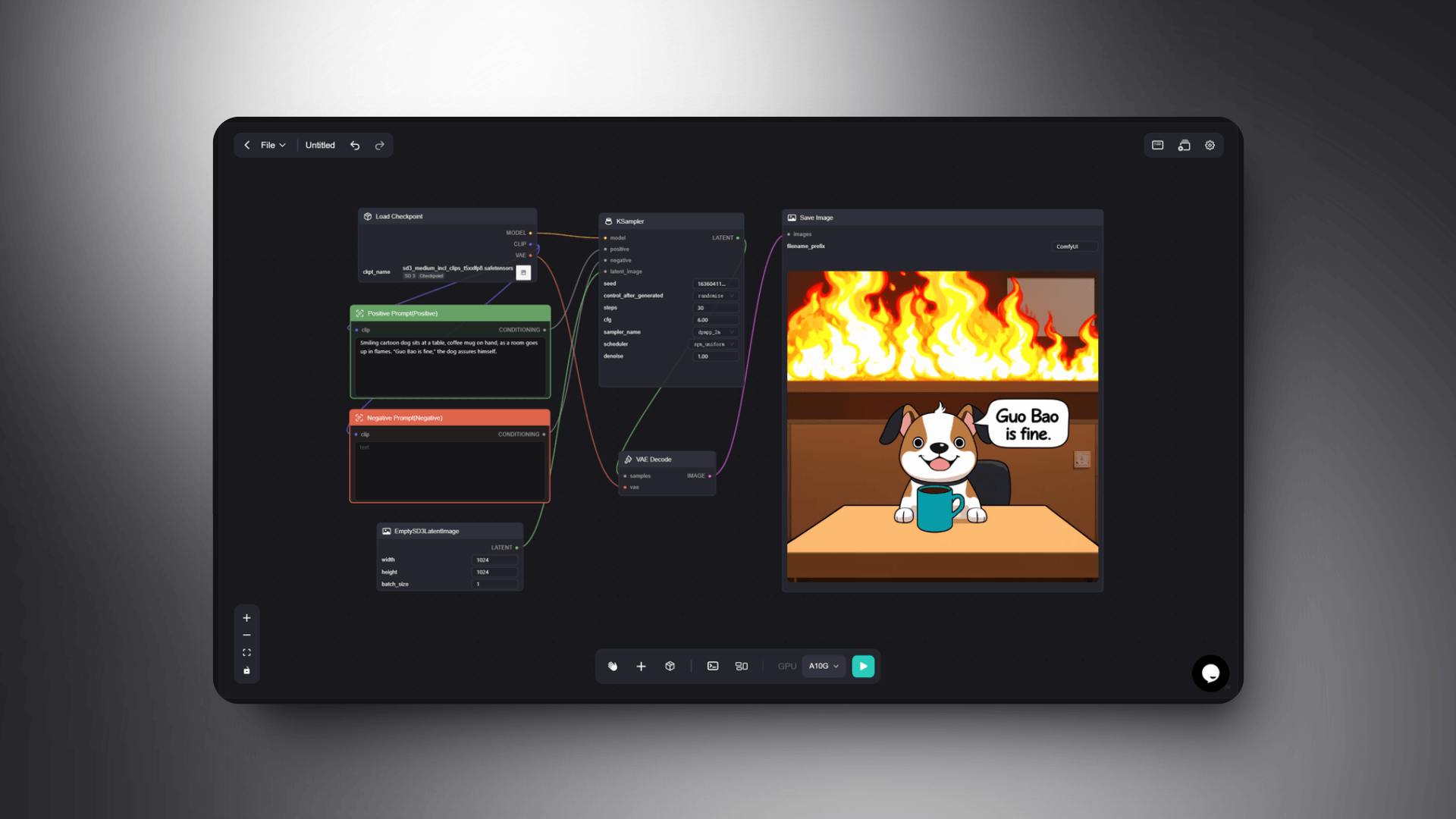
Prompt:Smiling cartoon dog sits at a table, coffee mug on hand, as a room goes up in flames. “Guo Bao is fine,” the dog assures himself.
SD3 Triple Clip Model Workflow
The accuracy of the generated results using the three SD3 models does not vary significantly; the main difference lies in their ability to understand prompts. Compared to sd3_medium.safetensors, sd3_medium_incl_clips.safetensors and sd3_medium_incl_clips_t5xxlfp8.safetensors exhibit relatively stronger prompt understanding capabilities.
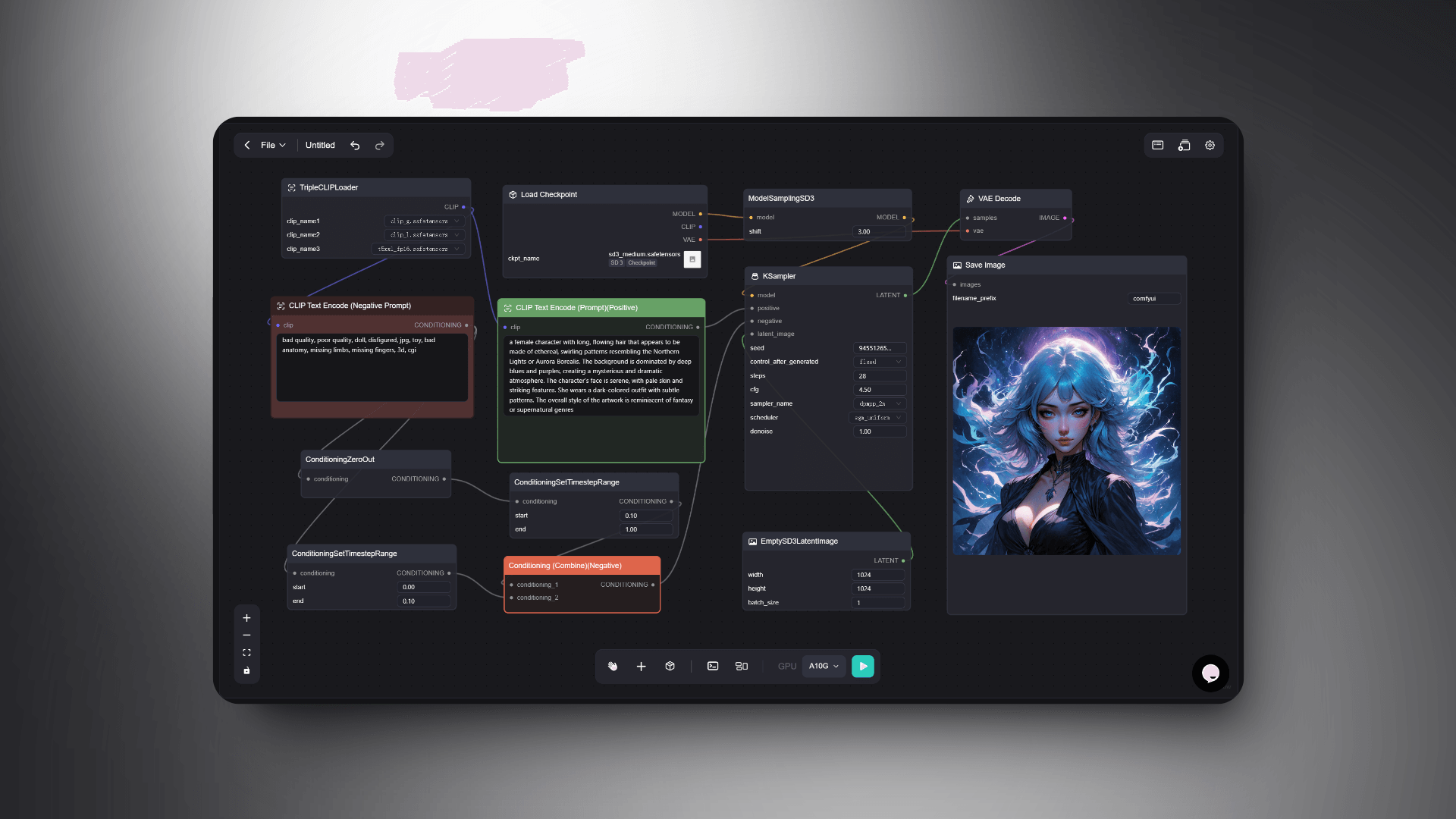
Prompt:a female character with long, flowing hair that appears to be made of ethereal, swirling patterns resembling the Northern Lights or Aurora Borealis. The background is dominated by deep blues and purples, creating a mysterious and dramatic atmosphere. The character's face is serene, with pale skin and striking features. She wears a dark-colored outfit with subtle patterns. The overall style of the artwork is reminiscent of fantasy or supernatural genres
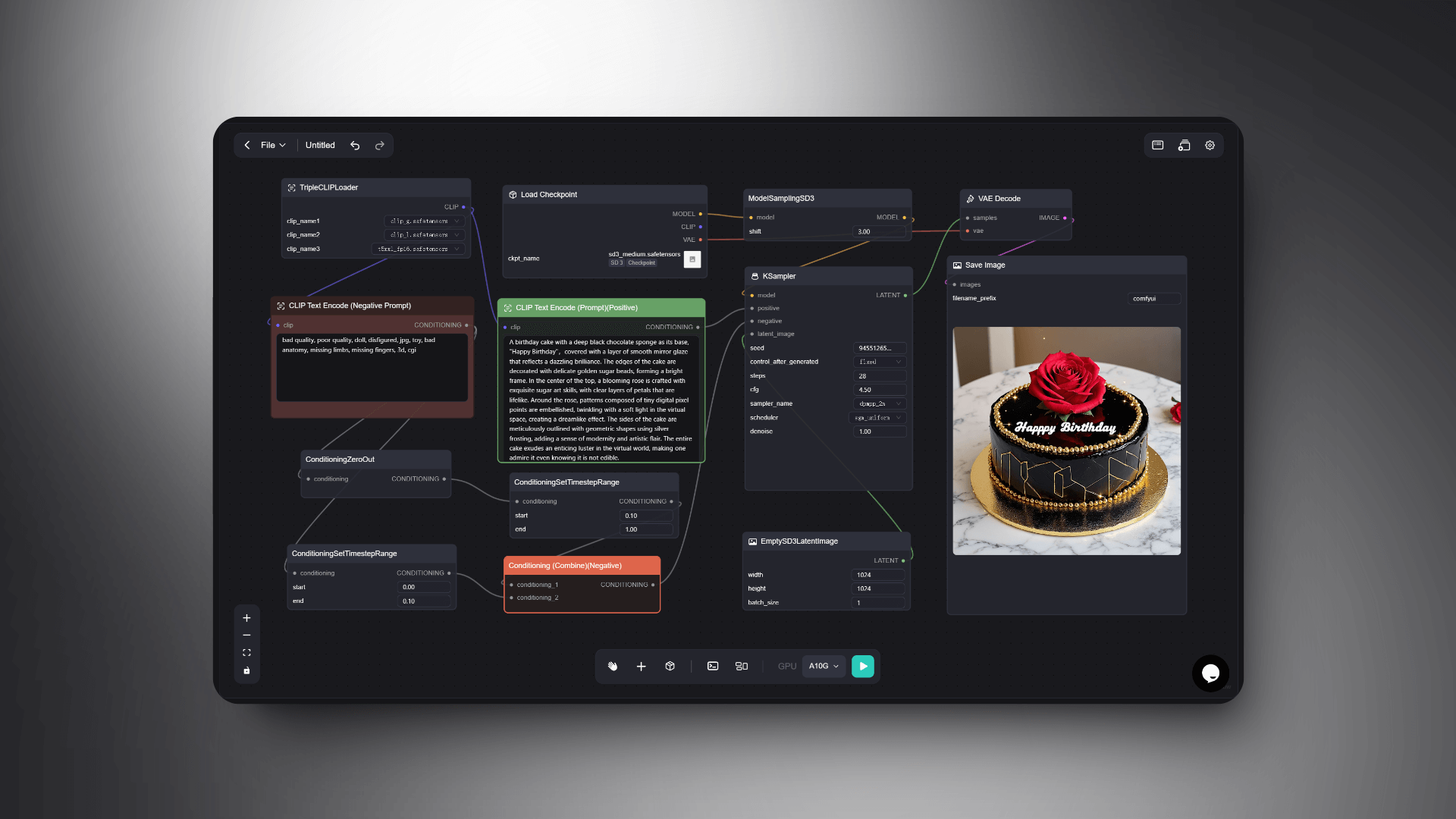
Prompt:A birthday cake with a deep black chocolate sponge as its base, "Happy Birthday",covered with a layer of smooth mirror glaze that reflects a dazzling brilliance. The edges of the cake are decorated with delicate golden sugar beads, forming a bright frame. In the center of the top, a blooming rose is crafted with exquisite sugar art skills, with clear layers of petals that are lifelike. Around the rose, patterns composed of tiny digital pixel points are embellished, twinkling with a soft light in the virtual space, creating a dreamlike effect. The sides of the cake are meticulously outlined with geometric shapes using silver frosting, adding a sense of modernity and artistic flair. The entire cake exudes an enticing luster in the virtual world, making one admire it even knowing it is not edible.

You can see that SD3 demonstrates excellent capabilities when handling long text prompts. Compared to using keywords as prompts, SD3 shows better understanding of the semantic meaning of paragraph texts.
SD3 + Portrait Master Workflow
This workflow primarily utilizes the SD3 model for portrait processing. You can customize various aspects of the character such as age, race, body type, pose, and also adjust parameters for eyes and lips color and shape. It allows customization of makeup, face shape, hair (hairstyle, length, volume), facial details (skin texture, pores, dimples, freckles, moles), lighting, and more.
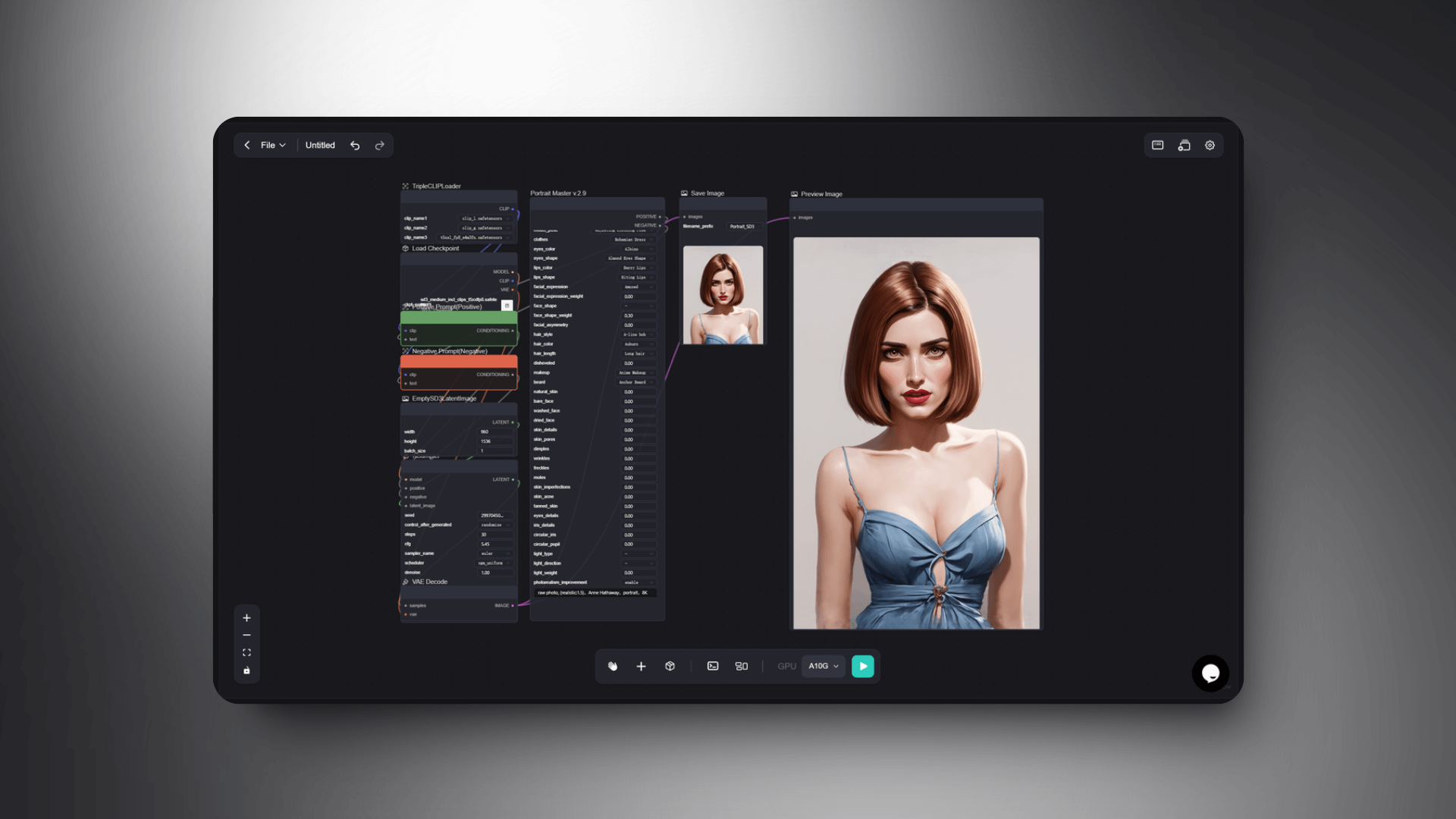
I attempted to customize the character's features, changing hairstyle, makeup, and attire, altering the generated image style, and so on. The advantage of Portrait Master v.2.9 nodes is that each option can be individually selected, offering high flexibility. The options for adjusting portraits are also comprehensive.

You can also enhance other aspects such as filters, color adjustments, and detail enhancements while customizing the character's appearance, creating a softer and more natural look in the portrait photo.

Comparison between SD3 and SDXL
When I used SD3 and SDXL models with the same parameters and prompts to generate images, there wasn't a significant difference in the final results. However, in handling long text prompts, SD3 demonstrated better understanding. With identical prompts, the SDXL model occasionally resulted in image distortions.

Prompt:selfie photo of a wizard with long beard and purple robes, he is apparently in the middle of Tokyo. Probably taken from a phone.

Prompt:photo of a young woman with long, wavy brown hair tied in a bun and glasses. She has a fair complexion and is wearing subtle makeup, emphasizing her eyes and lips. She is dressed in a black top. The background appears to be an urban setting with a building facade, and the sunlight casts a warm glow on her face.

Prompt:anime art of a steampunk inventor in their workshop, surrounded by gears, gadgets, and steam. He is holding a blue potion and a red potion, one in each hand.