How to choose the right model?
You might encounter a variety of models shared on various social media platforms, or on AI model-sharing websites. Websites like Civitai (opens in a new tab) might offer thousands of models for download.
Many people may wonder, which model is right for me? This blog post will share some of my thoughts on the matter.
1. Determine the Model Type
First, you need to determine your needs, and then download different models based on those needs.
Depending on your requirements, common types of models include:
- Base Models: The most common AI text-to-image models that generate images based on your text prompts. Examples include Stable Diffusion v1.5, Stable Diffusion XL, etc.
- LoRA Models: You can understand these as a kind of filter model. They can generate more special images, like loading a line-art LoRA model in your workflow to generate line-art style images. There are also LoRA models that allow AI to generate images of people with specific appearances, such as some celebrities' LoRA. Using these models allows you to generate specific celebrities' likenesses. It's important to note that these models require a Base Model to work, meaning you need to download a Base Model first before using a corresponding LoRA model.
- Inpainting Models: If you want to modify an image, like to remove an object or to repair an object, then you will need to use an Inpainting model. This type inputs an image and a mask, and the AI repairs the picture based on the mask. This model can be used independently.
- Upscale Models: If you want to enlarge an image, then you will need to use an Upscale model. This model takes an image and a multiplier, and the AI enlarges the image based on the multiplier. This model can also be used independently.
- ControlNet Models: If you want to control the position of an object in an image, or the pose of a person, then you will need to use a ControlNet model. However, similar to the LoRA model, it can't be used without a Base Model.
- Video Generation Models: This type of model turns images into videos based on your text commands.
2. Check Your Computer Configuration
After you've determined the type of model you need, you can further filter models based on that type. However, before you do so, I'd like to point out an often overlooked factor: your computer's specifications.
AI image generation models require substantial computational resources. If your computer's specs aren't sufficient, you may not be able to run the model, or it might run very slowly, taking 30 to 40 seconds to generate a single image. According to the mentioned model types, the requirements for your computer configurations can differ.
The models that have the biggest impact on specifications are Base, Inpainting, and video generation models. Currently, there isn't a universal official set of system requirements for running AI models, but based on my experience:
- Base & Inpainting Models:
- For Windows PCs with less than 6GB of VRAM, or M series MacBooks with less than 16GB memory, I recommend using Stable Diffusion v1.5 or models fine-tuned from it.
- If your computer has better specs, with more than 8GB VRAM, or M series MacBook with more than 16GB memory, I recommend using Stable Diffusion XL or models fine-tuned from it.
- If you want to use video generation models or image-to-video models, then it's best to have more than 16GB VRAM and ideally an Nvidia graphics card—otherwise, it might be difficult to run the models.
How do you know whether the model you wish to download is based on Stable Diffusion v1.5 or Stable Diffusion XL? Usually, the model-sharing website will indicate it. On Comflowy's model sharing page, there will be a Base Model tag that shows whether the model is based on Stable Diffusion v1.5 or Stable Diffusion XL.
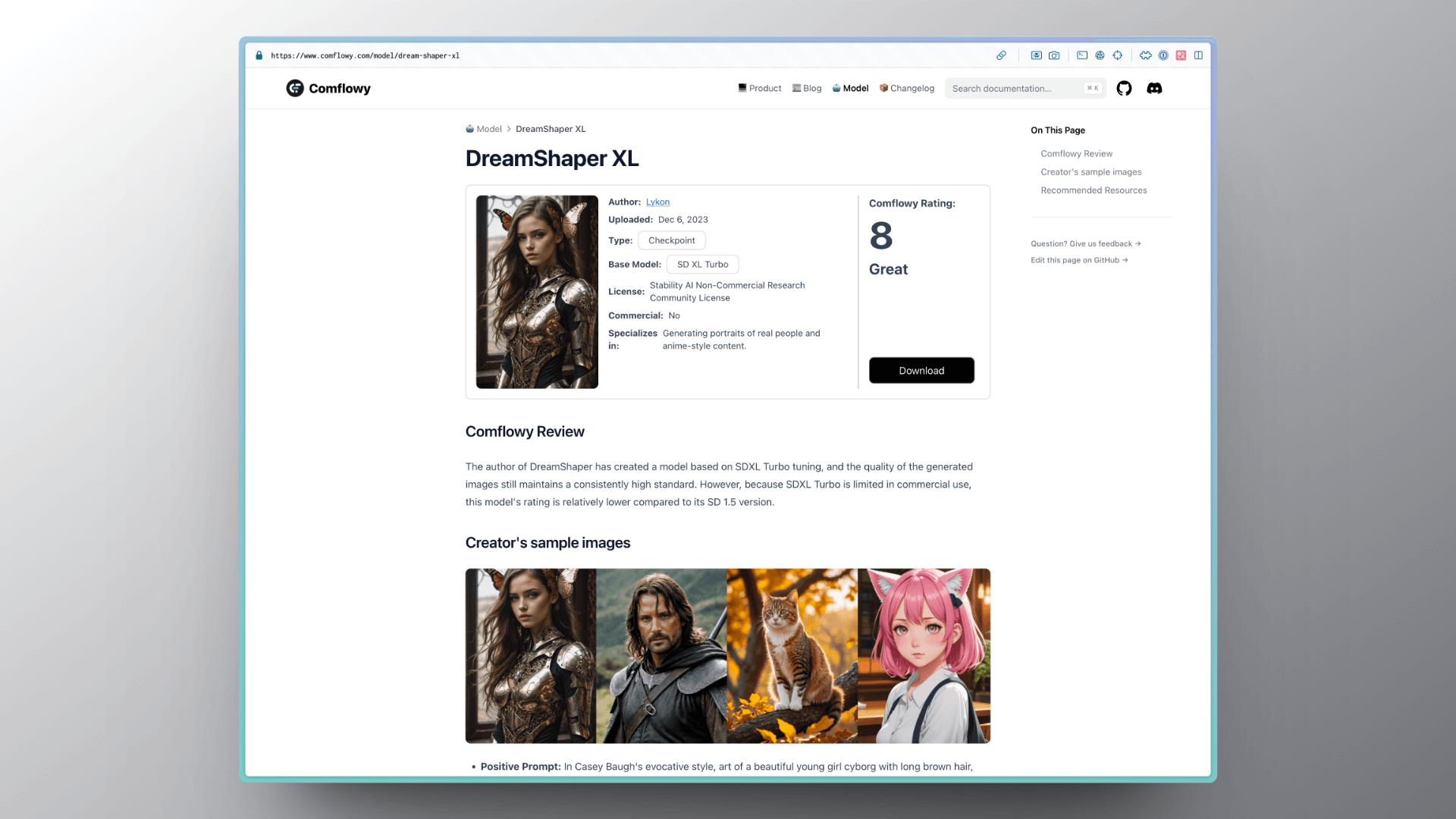
3. Pay Attention to Model Companions
After determining your computer's specs, you can then go on to select the model you need. As I mentioned earlier, for computers with lower specs, I would suggest using models based on Stable Diffusion v1.5 or fine-tuned from that model.
Usually, people download models from sharing websites, and then judge the quality of a model by its number of downloads or reviews. While this is a good approach, I believe there's another factor to consider—model companions.
What does that mean? Let's take these two models as an example. The base models for both are Stable Diffusion v1.5, and they are both in a realistic style. The model on the left has higher download and review numbers compared to the one on the right.
Generally, everyone would go for the model on the left. But if the effect of both models is similar, I would recommend the model on the right.
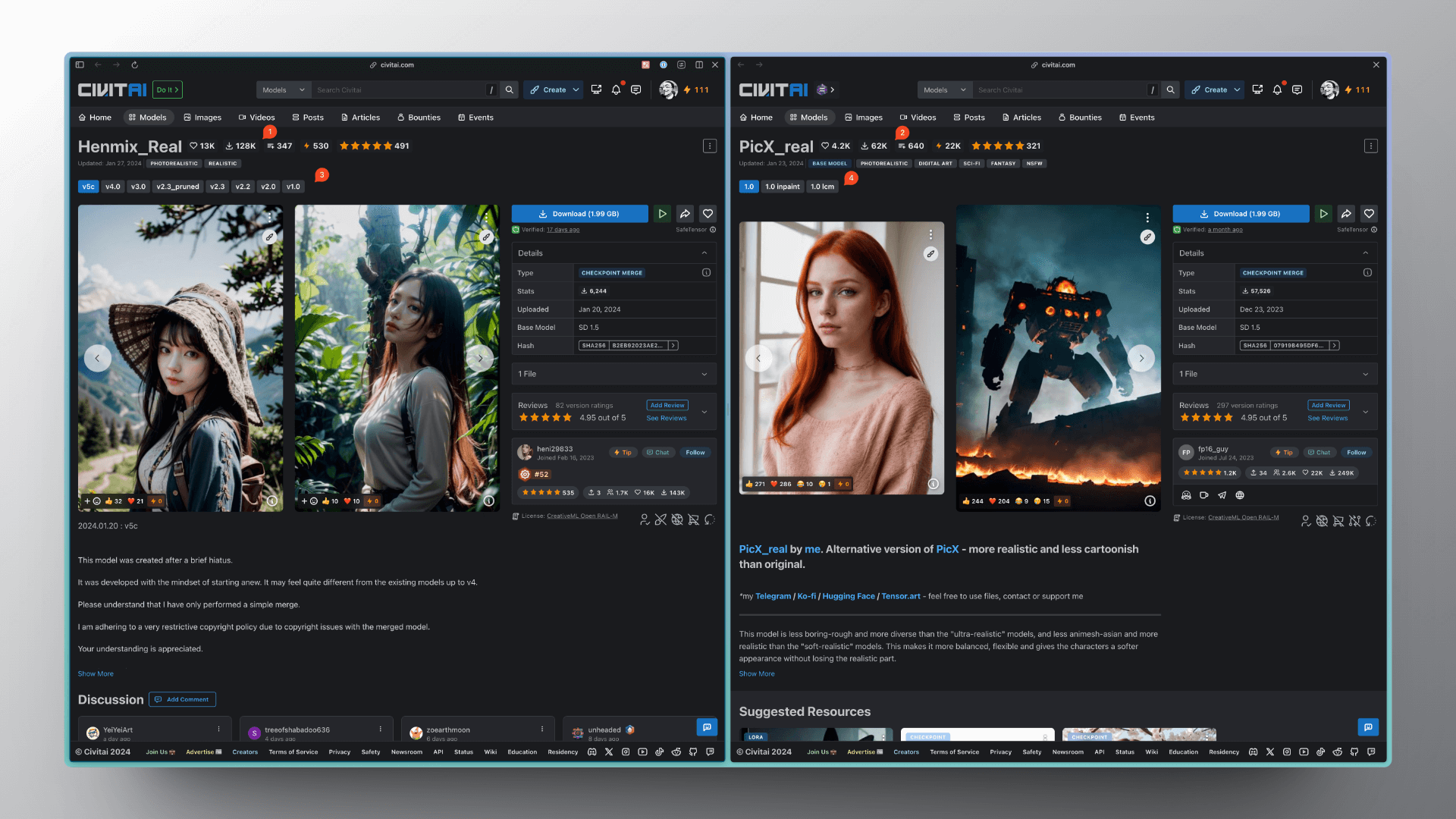
Because the model on the right offers more companions, such as Inpainting and LCM models, while the left model, although updated more frequently, only updated the Base model. Let me give you a practical example to understand the importance of companions.
If you used the model on the left to generate an image but found some content inappropriate, such as the hair color of the person is not what you wanted, you'd have to generate the image again by modifying the prompt. Although the new person's hair color might be correct, the other content may also change. Of course, you could also use another Inpainting model to fix the image, but since it's generated with another Inpainting model, the effect might not be as good. However, if you use the model on the right, you can use its Inpainting model, without needing another one, ensuring consistency in style.
4. My Recommendations
If you are a beginner, I would recommend using the DreamShaper model. It has a Base model based on SDv1.5 and a version based on SDXL. It also comes with good companion models like Inpainting and LCM models, and the generated results are very good.

