AI Weekly #004
🆕 更新了什么?
产品更新:
- 支持导出 workflow。
- 应用支持自动更新。
- 修复了各种安装错误问题。
- 修复了一些 UI 显示错位问题。
- 修复了导出图片不带 workflow 参数的问题。
上周新增教程:
- 如何将 ComfyUI 应用于室内设计? (opens in a new tab):挖掘了 ComfyUI 在室内设计中可以有哪些出色表现,同时我们也推荐了一些模型和插件,帮助对室内设计感兴趣的人更好的使用。
- 模型推荐 (opens in a new tab):考虑到很多新学员常常问有何模型可以推荐。所以教程网站新增了模型推荐页面,后续会持续推荐更多合适大家使用的模型。
🤩 每周 AI 精选
📄 值得关注的论文 & 技术
它是一个利用 LLM(Large Language Model)优化 SD (Text-to-Image) 文本到图像的转换过程的框架。该框架能够更好地理解和分解生成图像的文字提示,以实现将一幅图像分解成不同的部分或区域,并根据理解的相应文本提示来生成图像,最后合成为一个符合预期要求的图像。RPG 框架的主要功能包括多模态重标记、思维链规划、补充区域扩散、高分辨率图像生成、多样化应用以及对不同类型的大语言模型的兼容性。因为它使用先进的大型语言模型,该框架可以直接应用于文本到图像的转换任务,无需进行额外的模型训练。

它只需一张人脸照片 几秒钟就能生成不同风格的人物照片,与传统方法需要多张参考图像和复杂的微调过程不同,InstantID 只需一张图像,而且无需复杂的训练或微调过程。能够满足高保真度的个性化图像生成,无需复杂的训练或微调过程。兼容性强,面部保真度和文本编辑性高,应用场景多样化、实用性和效率高、支持多重参考以获得更多的信息和灵感,增强生成图像的丰富性和多样性。

利用多张照片作为身份 ID,获取人物特征,然后创造出一个新的、个性化的人物图像。能根据描述生成符合描述的人物照片,也能把几个不同人的照片特征混合在一起,创造出一个全新的人物形象。还能改变照片人物的性别、年龄和生成多种风格的其他照片。快速逼真,效果自然。

由 LLM 驱动的文本到图像生成系统,由字节跳动开发,DiffusionGPT 的厉害之处在于它集成了多种领域的专家图像生成模型。然后使用 LLM 来对接这些图像生成模型,让 LLM 来处理和理解各种文本提示(包括具体的指令、抽象的灵感、复杂的假设等),最后根据理解的信息选择最合适的图像模型来生成图像。

🛠️ 值得尝试的产品
推出三项新功能:文本到图像、背景去除和橡皮擦。利用这三个工具你可以轻松的编辑任何图像,同时也可以使用他们对各种图像进行自由组合。你在左边使用工具进行操作,右边 AI 会自动实时的生成图像,大大提高了创作的便捷性和自由度,真正的天马行空...
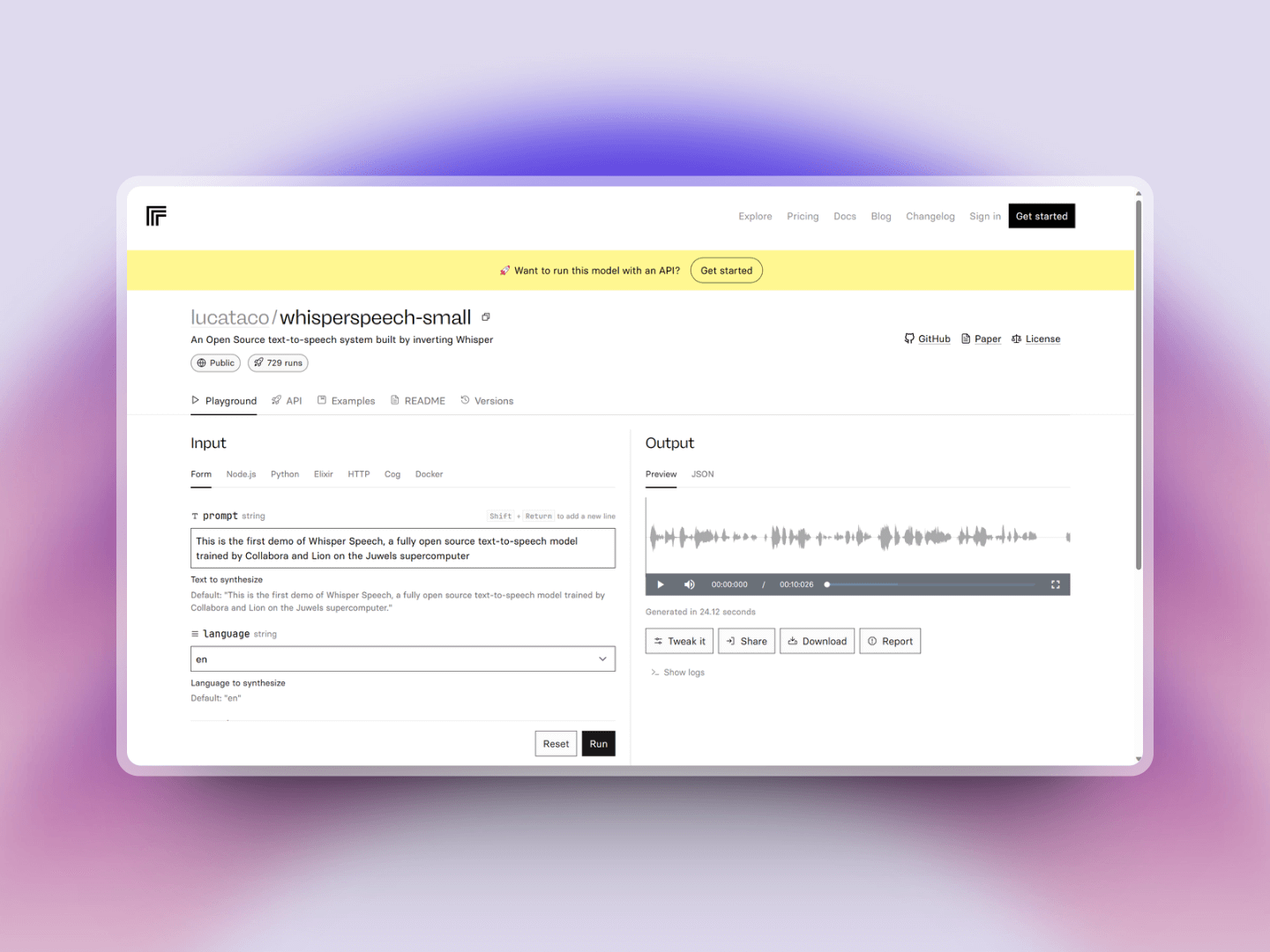
一个开源的文本到语音系统,它是通过对 OpenAI 的 Whisper 语音识别模型反向工程来实现的。通过这种反转过程,WhisperSpeech 能够接收文本输入,并利用修改后的 Whisper 模型生成听起来自然的语音输出。输出的语音在发音准确性和自然度方面都非常的优秀。
Multi Motion Brush 用于精确控制运动的工具。允许你在图像上使用不同的笔刷来控制图像各个部分的运动状态你可以选择不同的笔刷来添加或改变图像中的动作,每种笔刷都有自己独特的效果。
HeyGen 是一个在线的数字人视频制作平台,利用生成性 AI 的力量,简化了视频创作过程,可以快速轻松地创建专业级视频。他们还提供“视频翻译”的功能,通过“语言翻译 + 音色合成 + 卡点对口型”一气呵成,让歌星霉霉在视频中能说地道汉语。HeyGen 的最新功能演示可以看到,目前可以和 AI 进行视频聊天,就是你用文字可以和机器人对话,机器人有一个具象的形象,它可以通过视频来和你聊天!视频里的人物、声音和回答都是 AI 生成的。
