图生图
正式开始学习本章前,请先下载以下模型,并将模型文件放到对应的文件夹内:
- Dreamshaper (opens in a new tab):将其放到 ComfyUI 里的 models/checkpoints 文件夹内。
- stable-diffusion-2-1-unclip (opens in a new tab):你可以下载 h 或 l 版本,并将其放到 ComfyUI 里的 models/checkpoints 文件夹内。
- coadapter-style-sd15v1 (opens in a new tab):将其放到 ComfyUI 里的 models/style_models 文件夹内。
- OpenAI CLIP Model (opens in a new tab):将其放到 ComfyUI 里的 models/clip_vision 文件夹内。
如果你想要使用本章的工作流,可以使用下载使用 Comflowy 本地版,或者注册使用 Comflowy 云端版本 (opens in a new tab),里面都内置了本章的工作流。并且如果你使用的是云端版本,你可以直接使用我们内置的模型,无需下载。
完成基础篇的学习后,你可能对生成的图片不满意,比如觉得:
- 生成的图片分辨率不够。
- 觉得生成的图片部分内容不满意,想要对其进行修改。
- 亦或者觉得想要加强对生成过程的控制,比如想控制图中人物的姿势等。
中级篇将会介绍更多方法,帮助你解决以上问题。不过在讲解以上问题的解决方案之前,我想先介绍一下 Stable Diffusion 的另一个关键工作流:图生图。
原理介绍
Stable Diffusion 模型图生图主流方法有两种:
- 重绘(drawing over):将输入的图片做基底,用模型在其上重新生成新的图片。
- 参考(reference):将输入的图片作为参数,将其和 prompt 一起输入到模型中,然后生成新的图片。
字面上可能比较难理解,按照传统,我们对这两种方法进行可视化的解释。
方法一:重绘
首先回忆下 Stable Diffusion 的原理,文生图是将随机噪声图降噪成一张新的图。而图生图的则是先给输入的图片添加噪音,再用相同的方法将这个噪音图降噪成新的图片。大概的流程是这样的。其对应的 workflow 一般称为 Simple img2img workflow。
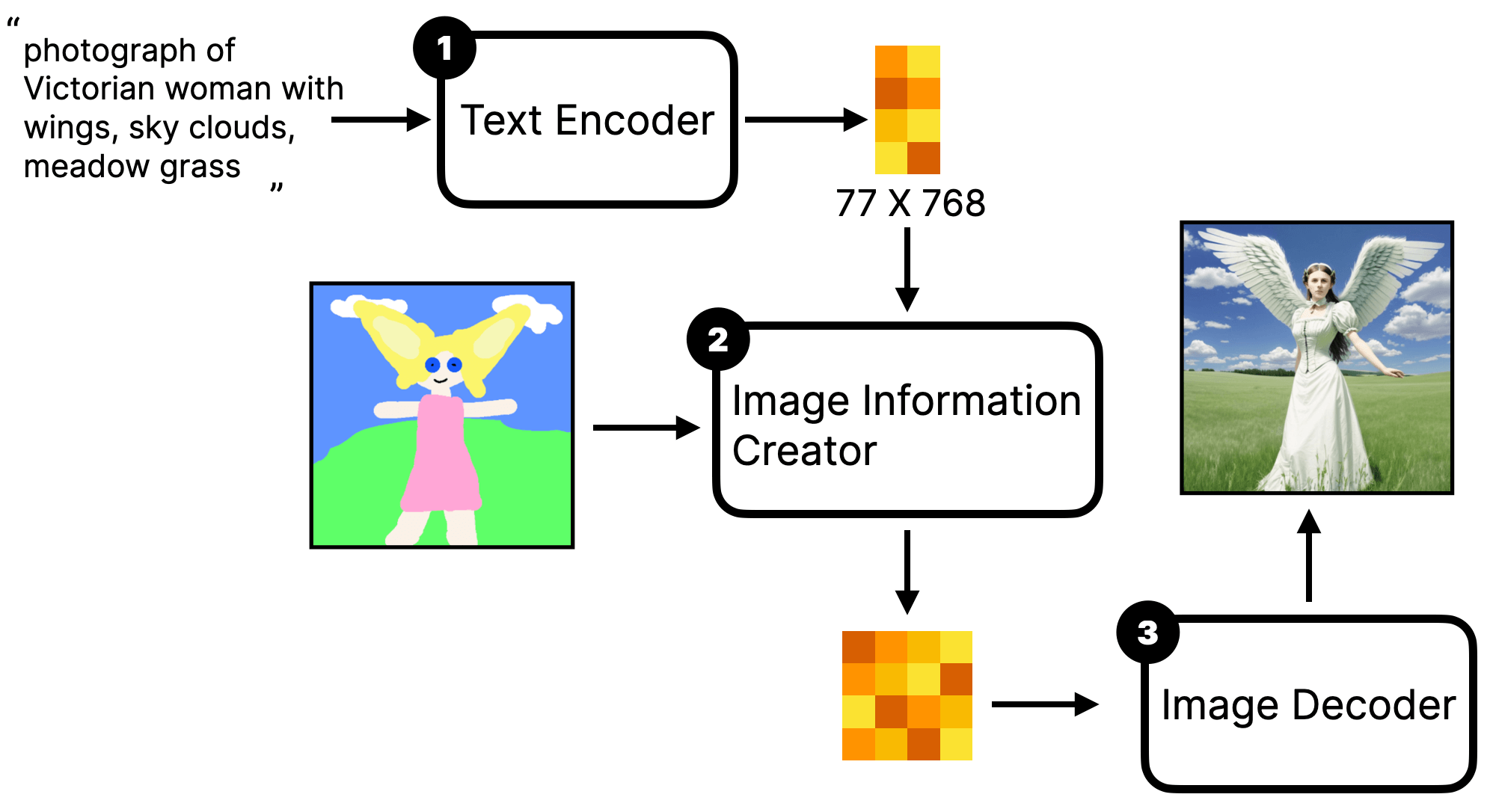
还是拿雕刻做类比的话,它的过程类似是雕刻师(模型)拿了一个雕像(初始输入的图),根据你的指令(Prompt)在其基础上重新雕一个雕塑(输出的图)。
方法二:参考
第二种方法则不是对输入的图片进行重绘,而是将输入的图片作为 prompt 的一部分,然后将其和文字 prompt 一起输入到模型中,最后生成新的图片。大概的流程是这样的:
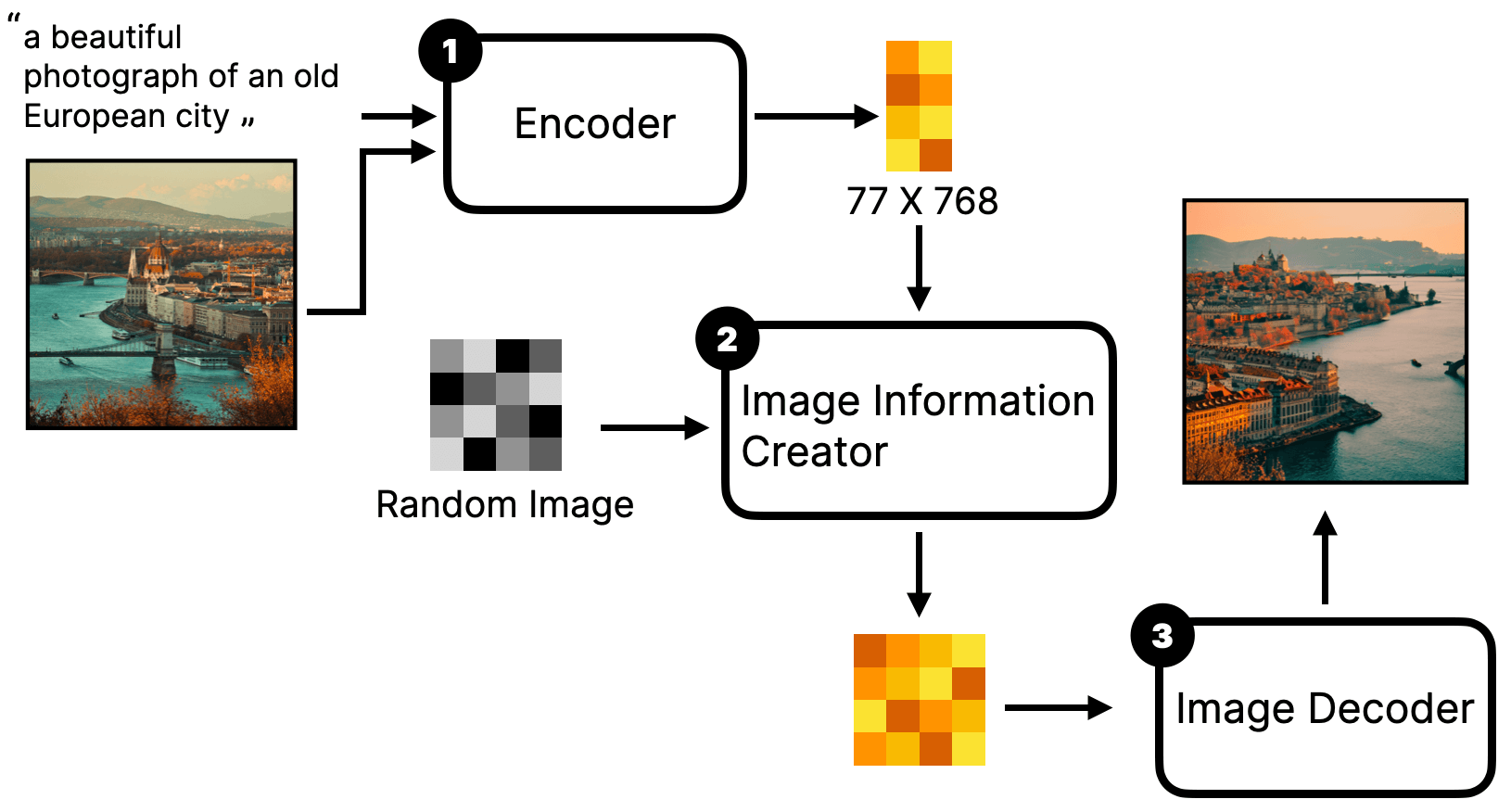
注意看,图中有一个与之前介绍的不一样地方,第一步不再是一个 Text Encoder 而是 Encorder。这其实很好理解,因为不止是文字 prompt 需要输入到模型,还有图片 prompt 需要输入。
如果那雕刻做类比的话,这个过程类似于你给雕刻师下了文字指令(prompt)外,还给雕刻师看了张图片,让 TA 参考一下,然后根据你的指令和图片重新雕刻一个雕塑(输出的图)。
另外,如何使用 Image 的数据,也会影响生成图片的效果:
- 如果你将图片作为文字 prompt 的补充,那生成的图片里也会包含原图里的元素。比如上面原理介绍的图里,我将一张有桥、河流、城墙的图输入给模型,而文字 prompt 并没有提到图里的这些内容。 但最终生成的图里却包含了原图里的信息(桥、河流、城墙),甚至风格也跟原图很类似。这种 workflow 一般称为 unCLIP model workflow。
- 另一种则是仅将原图的风格输入给模型,这样生成的图片就会有原图的风格,而不会有原图的内容。这种 workflow 一般称为 Style model workflow。
Simple img2img workflow
既然原理很简单,你应该能猜测出应该如何搭建 Simple img2img workflow。你不妨自己先试试,搭建一个 workflow 😎
- 关键在于需要将图片输入到 KSampler 里,而 KSampler 只能输入 latent 图片。
- 加载图片可以右键 → All node → image 里找到。
unCLIP model workflow
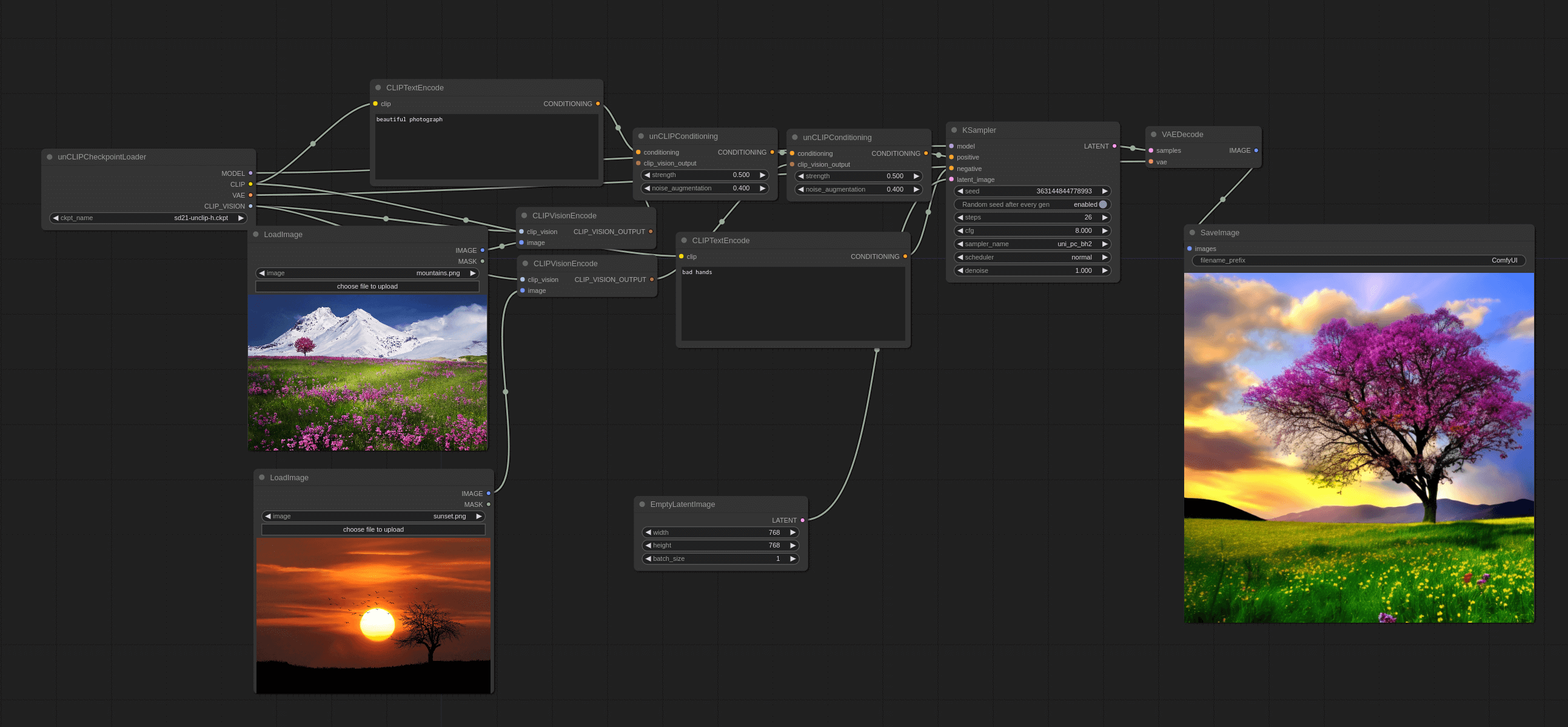
介绍完重绘,我们再来介绍参考。首先是 unCLIP model workflow,前面原理的部分没有细讲如何实现,我用 ComfyUI 的 workflow 详细解释一下。
添加 Load Image 节点
第一步,我们还是从 Default workflow 开始。然后在原有的基础上,添加加载图片节点,你可以右键 → All node → image 里找到此节点。
添加 CLIP Vision Encode 节点
第二步,我们需要将图片输入到模型中,所以需要将图片先 encode 成向量。所以我们要先添加 CLIP Vision Encode 节点,你可以右键 → All node → conditioning 里找到此节点。
然后我们可以将 Load Image 节点与 CLIP Vision Encode 节点相连。
添加 unCLIPCondtioning 节点
接着我们还要将图片 Encode 后的数据跟 Text Encode 的数据相融合,所以我们需要添加 unCLIPCondtioning 节点。你可以右键 → All node → conditioning 里找到此节点。
然后我们将 Positive prompt 与 unCLIPCondtioning 节点相连,再将 CLIP Vision Encode 与 unCLIPCondtioning 节点相连。接着将 unCLIPCondtioning 连到 KSampler 的 positive 处。
最后介绍下节点里的两个参数:
- strength:这是设置 prompt 的影响强度,数值越大,就越接近 prompt 的描述。它有点类似于你在 CLIP Text Encode 里写 Prompt 时会用到的权重写法,比如 (red hat:1.2)。
- noise_augmentation:这个主要是代表新图片与旧图片的相近程度。0 代表最相近,我一般会设置成 0.1 - 0.3。
替换 Load Checkpoint 节点为 unCLIPCheckpointLoader 节点
最后一步,你会发现,我们在第二步添加的 CLIP Vision Encode 节点还有一个点没有连,看文字是要连一个 Clip vision,其实它要连的是一个叫 unCLIPCheckpointLoader 的节点,你可以右键 → All node → loaders 里找到此节点。
然后将原来的 Checkpoint 删掉,将其替换为 unCLIPCheckpointLoader 节点,再将 CLIP Vision Encode 与 unCLIPCheckpointLoader 节点相连。并将其模型设置为 sd21-unclip-h 模型。
注意,虽然这个 loader 是叫 unCLIPCheckpointLoader,但你没法在 ComfyUI 的项目文件夹里找到该节点的文件夹,其实它跟 Checkpoint 节点共用一个文件夹。所以你需要将 unCLIP 的模型文件放到 Checkpoint 里。
你在下载 unCLIP 模型时,可以下载 h 或 l 版本,h 版本的模型生成的图片会更清晰,但生成速度会更慢。
还有需要将 Empty Latent Image 调整为 768x768,因为我们用的 unClip model 是基于 SD2.1 训练的。最后的 workflow 应该长这样:
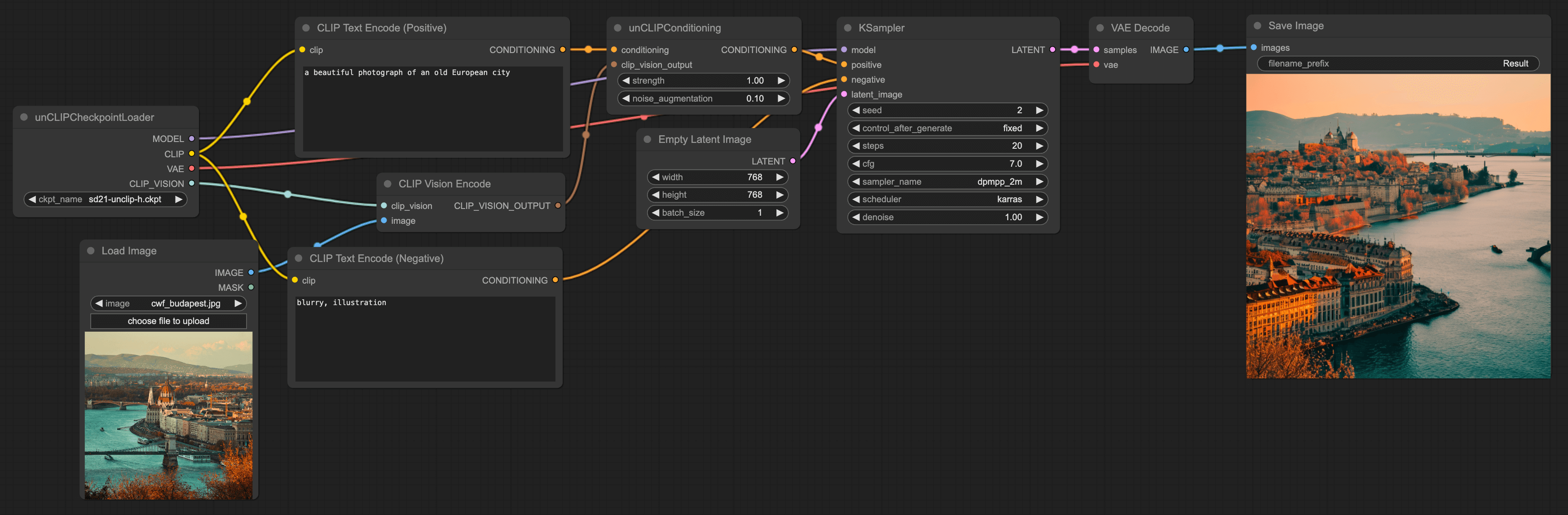
其实从 workflow 中不难看出,本质上来说,就是先将图片 encode 然后再将文字 prompt encode,最后将两者融合,再输入到模型中。这样生成的图片就会包含原图的元素。
另外,你还可以尝试将多张图片输入到模型中,生成的图片就会包含多张图片的元素。比如像这样:
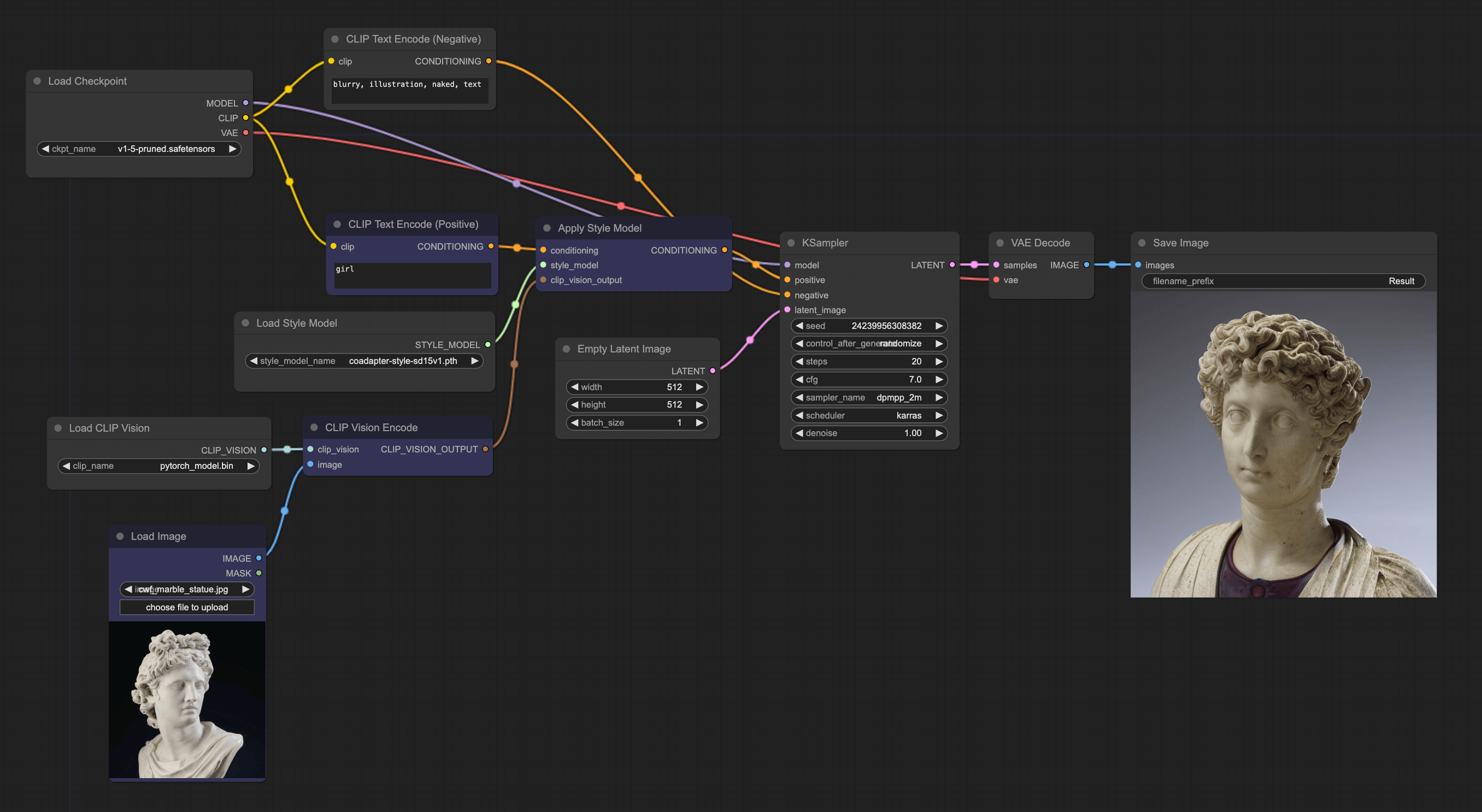
Style model workflow
另一种重绘,则是只用图片的风格,而不用图片的内容。其实现方法跟 unCLIP model workflow 很类似,只是需要将图片的内容去掉,只保留风格。我们来讲解下其 ComfyUI workflow:
更换节点
第一步,我们可以继续使用上一个案例的 workflow,但需要更换一些节点。第一个是将 unCLIPCheckpointLoader 换成 Checkpoint 并将模型切换成 v1.5。接着再将 unCLIPCondtioning 切换成 Apple Style Model 节点,这个你可以右键 → All node → conditioning → style_model 里找到。
接着就可以将这些节点连载一起,此时你会发现还有两个端点没连,我们进入下一步。
添加 Load CLIP Vision 和 Load Style Model 节点
右键 → All node → loaders 里能找到这两个节点,然后将他们分别连在 CLIP Vision Encode 节点和 Apply Style Model 上。连接完后,我们再来讲解下完整 Workflow, 整个流程还挺好理解的,输入图片,然后将图片进行 encode 后,使用 Apply Style Model 将图片里的 Style 信息过滤出来,并和文字 prompt 融合在一起并传给 KSampler。
与 unCLIP model workflow 不一样的地方就是它只用了 style。所以绘制的内容,不一定跟原图很像,但风格会比较像。
需要注意,这个 style model 只能理解常用的 style,名画或人物的图片效果会比较好,但如果导入的是一些小众,并且抽象的图,效果就会非常差。