Stable Diffusion 进阶
如果你想要使用本章的工作流,可以使用下载使用 Comflowy 本地版,或者注册使用 Comflowy 云端版本 (opens in a new tab),里面都内置了本章的工作流。并且如果你使用的是云端版本,你可以直接使用我们内置的模型,无需下载。
在基础篇我们介绍了 Stable DIffusion 的基础模型,进阶篇我们通过 ComfyUI 的 workflow 来介绍下 Stable Diffusion XL。
模型介绍
Stable Diffusion XL 是 Stable Diffusion v1.5 的进阶版本,它与之前的版本相比,主要有以下几个特点:
- 能生成更高质量的图片
- 图片的细节更丰富
- 能理解更复杂的 prompt
- 支持生成更大尺寸的图片
那它和之前的版本有何区别呢?让我们将其可视化:
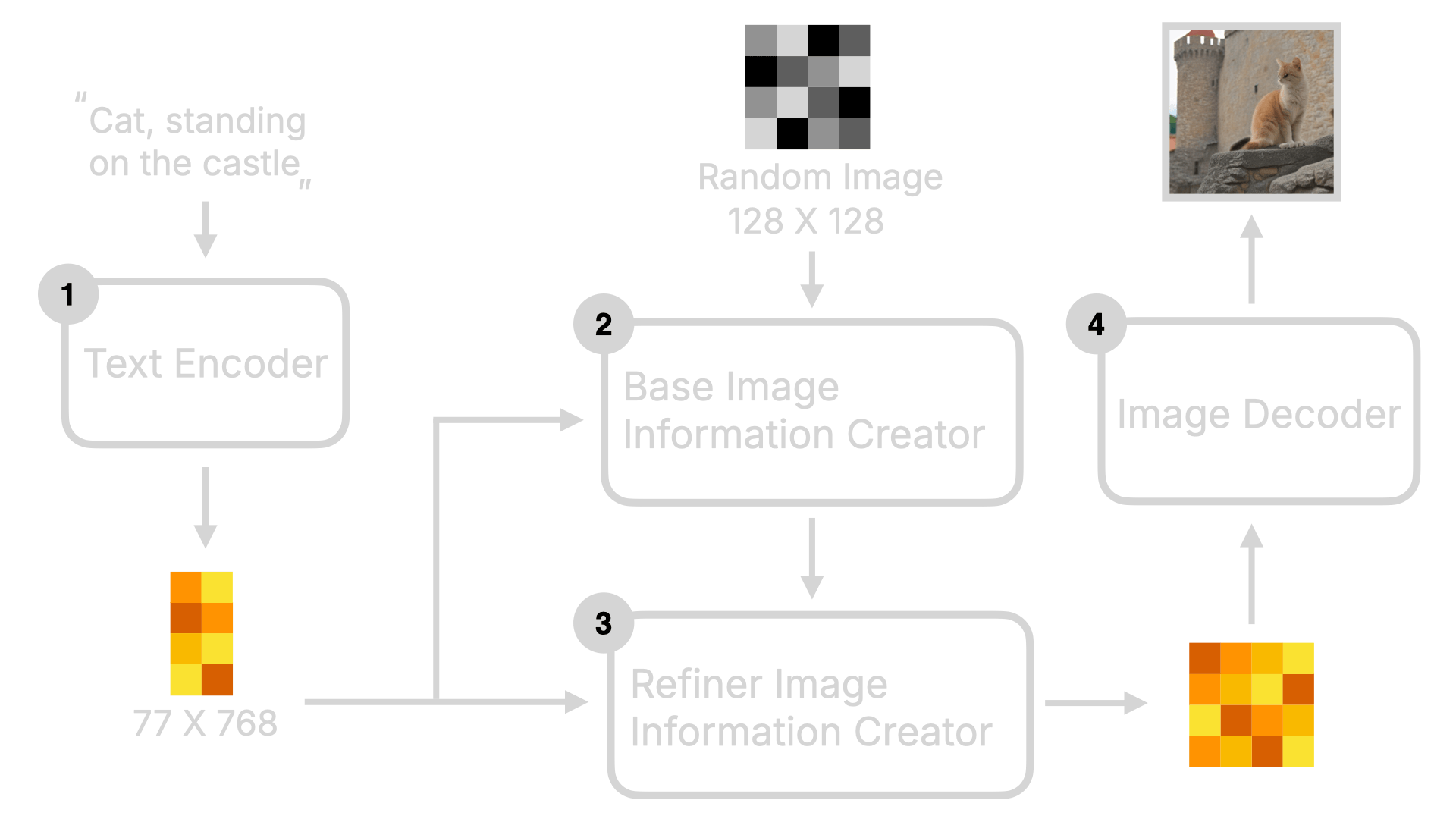
从图中可以看出,相较于 SD v1.5,SDXL 有两个 Image Creator。一个是 Base 模型,一个是 Refined 模型,这就是为何你在下载 SDXL 模型的时候,会看到两个模型的原因。Base 会先生成一个全局构图,然后 Refined 会在这个全局构图的基础上,生成更加细节丰富的图片。
这就是为何 SDXL 能生成更高质量的图片的原因。另外,SDXL 中的 CLIP 部分还使用了更大的 OpenClip 模型,所以它能理解更复杂的 prompt。
Stable Diffusion XL Workflow
简单介绍完模型后,我们再来看看如何使用 ComfyUI 搭建一个 SDXL 的 workflow。
你可能会疑惑,不是只需要将 checkpoint 节点里的模型换成 SDXL 模型就可以了吗?为何还要重新搭建 workflow? 重看上面的模型介绍,你会发现 SDXL 会用到两个模型,而在我们的之前的教程中,只是让大家使用一个模型来生成。而真正完整的是两个,所以 workflow 重新搭建。当然,如果你并不追求极致的效果,也可以只用 base。
Ok,言归正传。首先你需要下载 SDXL 的模型:
- SDXL 1.0 Base (opens in a new tab):将其放到 ComfyUI 里的 models/checkpoints 文件夹内。
- SDXL 1.0 Refiner (opens in a new tab):将其放到 ComfyUI 里的 models/checkpoints 文件夹内。
这里有两点需要注意:
- SDXL 的模型是两个,所以你需要将两个模型都下载下来。
- 你会看到文件名中有 0.9 vae 的模型文件,这个版本是包含更好的 vae 模型,我会更推荐你下载这个版本。
下载好后,我们再打开 ComfyUI,先加载 Default workflow。然后我们一步步地来搭建 SDXL 的 workflow。
将 KSampler 替换为 KSampler Advanced
首先我们需要将 Default workflow 里的 KSampler 删除,然后双击空白处,搜索 KSampler,然后选择 KSampler Advanced,将其添加到 workflow 中。另外,正如我在前面模型介绍中提到的那样,SDXL 是由两个模型组成的,所以除了替换第一个外,你还需要额外添加一个。 同时因为是先用 Base 再用 Refined,所以我们需要将两个 KSampler 连起来。最后的样子应该类似这样:
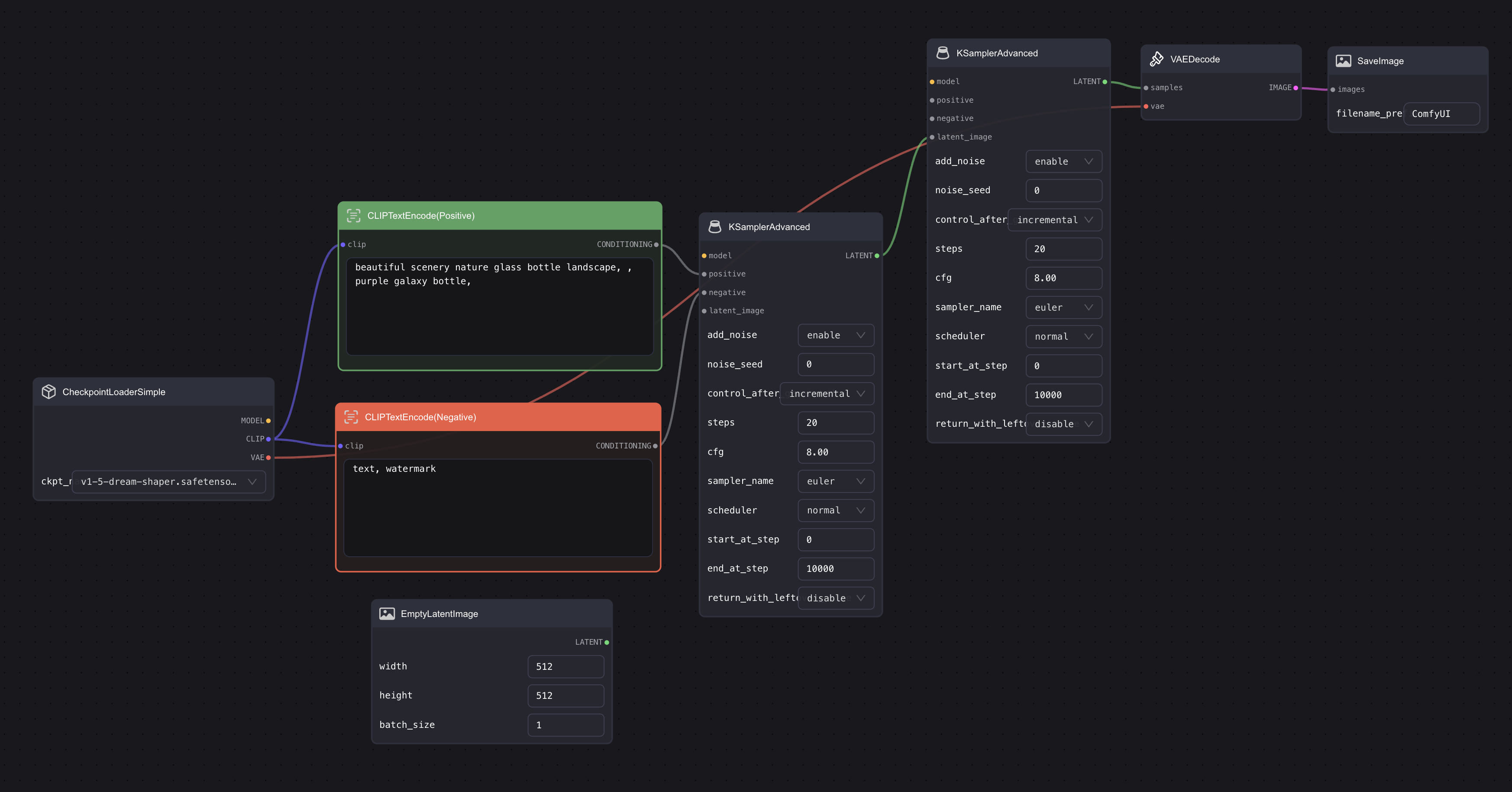
添加一个 Checkpoint
然后再添加一个 Checkpoint 节点,并连接到第二个 Ksampler 节点中。第一个 Checkpoint 选 base,第二个选 refiner,然后将第二个 Checkpoint 的 vae 与 vae encode 节点相连,最后的样子应该类似这样:
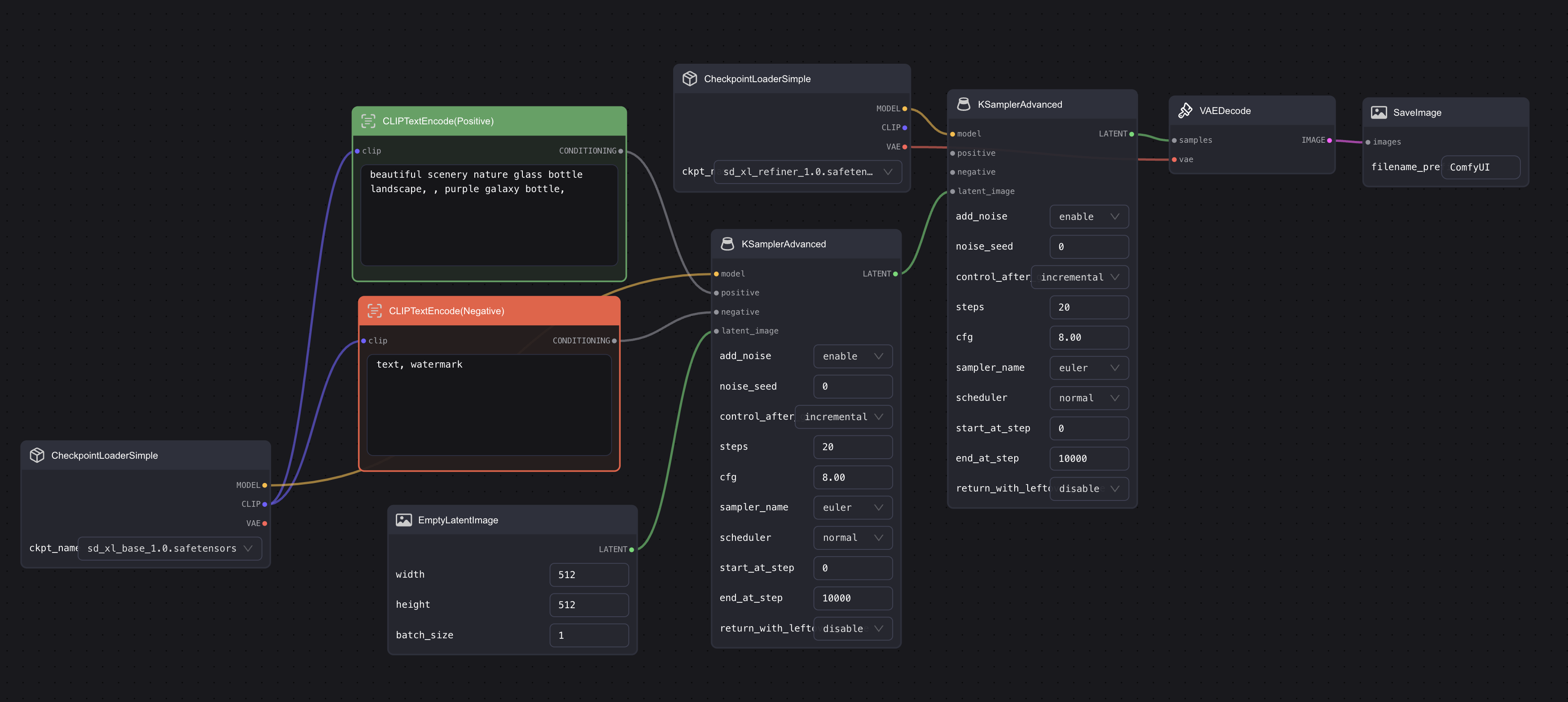
这一步 Vae 你可以使用带 0.9vae 的模型,另外,使用 base 的也可以,不一定要像我那样跟第二个 Checkpoint 相连。
连接 CLIP Text Encode 节点
既然有两个 Ksampler 那就意味着要连两组 CLIP Text Encode 节点。简单方法是,搞两组 CLIP Text Encode 节点,然后将两组 CLIP Text Encode 节点的 output 分别连到两个 KSampler 节点的 positive 和 negative input。
但这样的话,每次修改 prompt 都需要你手动输入两次,这样就会很麻烦。所以,我这里介绍一个更简单的方法。我们只需要搞一组 Prompt 输入框即可。
首先,双击空白处,搜索 string,将 Primitive STRING 添加到 workflow 中。接着右键点击其中一个 CLIP Text Encode 节点,选择 Convert text to widget,然后 CLIP Text Encode 节点的输入框会消失,并且输入端会多一个 Text input。此时我们将这个 Text input 与我们刚刚添加的 Primitive STRING 连起来。 你需要重复上面的步骤,接着再添加两个 CLIP Text Encode 节点,然后与第二个 KSampler 相连,并跟之前添加的 Primitive STRING 相连。最后的样子应该类似这样:
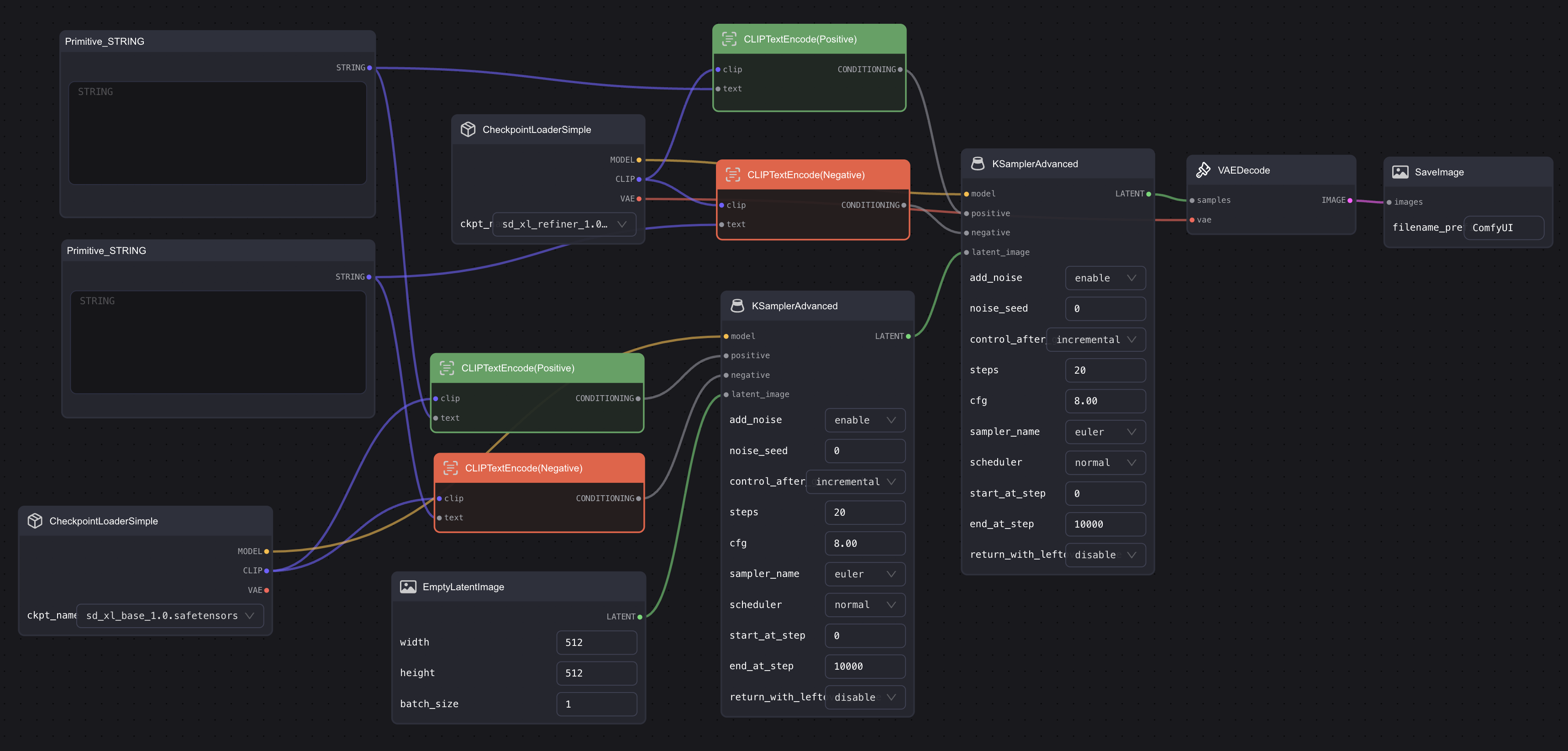
调整 KSampler 节点
目前 Comflowy 还在适配 Primitive 节点,所以如果你要用这个 workflow,可能需要你自己手动多次调整。或者转去使用 ComfyUI。
除了 Prompt 会重复外,KSampler 上还有不少参数是调整比较频繁的。跟 CLIP Text Encode 的情况类似,调整一次就要两个一起调整,比较麻烦,所以我们可以采用类似的做法将共用的参数放到一起。
首先,我们来配置下最常调整的 steps。右键点击 KSampler,然后选择 Convert steps to widget。接着双击空白处,搜索 Primitive,然后将这个 Primitive 与两个 KSampler 的 steps 相连。当你将 Primitive 连上 KSampler 后,Primitive 节点会发生变化,这是正常现象。为了方便后续使用,你可以将这个 Primitive 节点名称改成 Total Steps。右键 Primitive 节点,然后点击 Title 即可改名。
然后我们使用相同的方法将 Sampler 和 Scheduler 都用一个 Primitive 替代,并将节点改名。
接着,我们还要将第一个 KSampler 的 end_at_step 和第二个 KSampler 的 start_at_step 都 Convert to widget,然后与一个 Primitive 相连(注意,第一个是 end,第二是 start)。最后将第一个 KSampler 的 add_noise 和 return_with_leftover_noise 设为 enable,第二个 KSampler 的 add_noise 设为 disable。最后的样子应该类似这样:
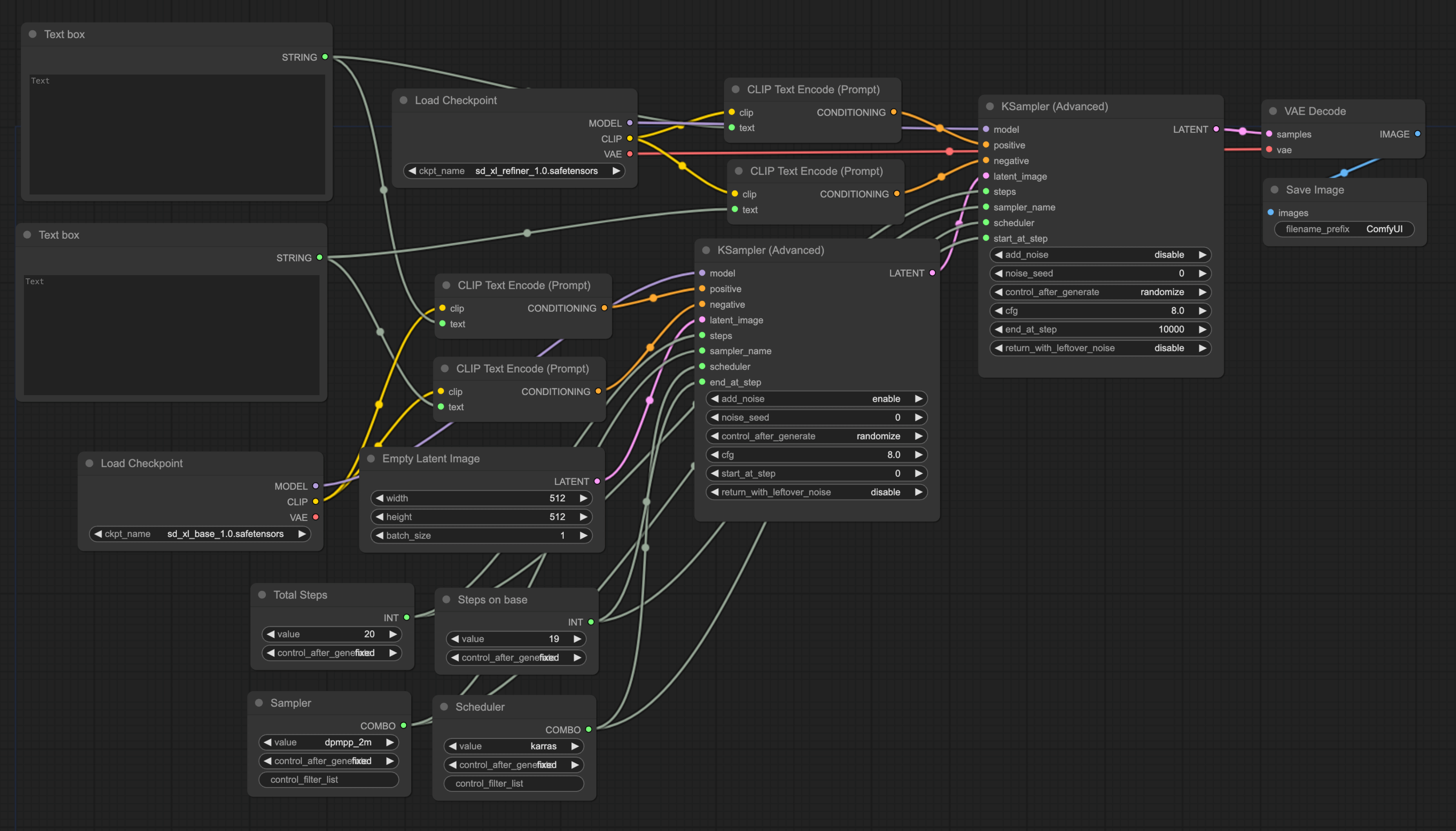
解释下最后两个设置,正如最前面的模型介绍中提到的那样,SDXL 是由两个模型组成的,并分别运行一定的 steps,为了让总 steps 等于 25,第二个 KSampler 就不能从 0 开始,而是要接着第一个 KSampler 的 steps 运行。所以我们需要将第二个 KSampler 的 start_at_step 设为与第一个 KSampler 的 end_at_step 一致。
另外,前面的模型介绍里有提到,refiner 的作用是基于 base 生成的图进行细化,那就意味着在 refiner 没有必要再添加额外的 noise。所以将第二 KSampler 的 noise 设置都设为 disable。
调整 Empty Latent Image 节点
最后,为了获得最好的图片效果,Empty Latent Image 节点的参数需要调整为 1024X1024。
最后,我们来对比下,同样 prompt 下,只有 base 和 两个一起用的区别。左图是 base,右图是 base + refiner,右图是不是更自然,且更精细一点呢?
